
Better Memory Tiering, Right from the First Placement
Tricks to avoid migration

Better Memory Tiering, Right from the First Placement João Póvoas, João Barreto, Bartosz Chomiński, André Gonçalves, Fedar Karabeinikau, Maciej Maciejewski, Jakub Schmiegel, and Kostiantyn Storozhuk ICPE'25
This paper addresses the first placement problem in systems with multiple tiers of memory (e.g., DRAM paired with HBM, or local DRAM paired with remote DRAM accessed over CXL).
The paper cites plenty of prior work which dynamically migrates pages/allocations out of suboptimal memory tiers. What is different about this paper is that it attempts to avoid placing data in a suboptimal tier in the first place. The key insight is: statistics from one allocation can be used to generate better placements for similar allocations which will occur in the future.
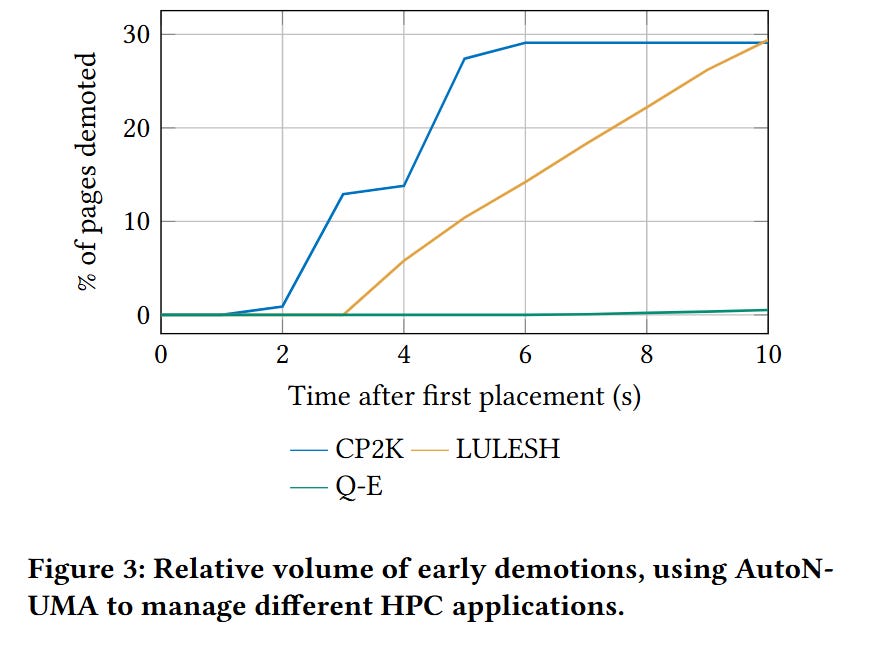
Fig. 3 offers insight into how much waste there is in a policy which initially places all pages into a fast tier and then migrates them to a slower tier if they are accessed infrequently. The figure shows results from one migration policy, applied to three benchmarks.
Allocation Contexts
This paper proposes gathering statistics for each allocation context. An allocation context is defined by the source code location of the allocation, the call stack at the moment of allocation, and the size of the allocation. If two allocations match on these attributes, then they are considered part of the same context.
The system hooks heap allocation functions (e.g., malloc, free) to track all outstanding allocations associated with each allocation context. The x86 PMU event MEM_TRANS_RETIRED.LOAD_LATENCY_GT_16 is used to determine how frequently each allocation context is accessed.
A tidbit I learned from this paper is that some x86 performance monitoring features do more than just count events. For example, MEM_TRANS_RETIRED.LOAD_LATENCY_GT_16 randomly samples load operations and emits the accessed (virtual) address. Given the accessed address, it is straightforward to map back to the associated allocation context.
The hotness of an allocation context is the frequency of these access events divided by the total size of all allocations in the context. Time is divided into epochs. During an epoch, the hotness of each allocation context is recalculated. When a new allocation occurs, the hotness of the allocation context (from the previous epoch) is used to determine which memory tier to place the allocation into.
The paper only tracks large allocations (at least 64 bytes). For smaller allocations, the juice is not worth the squeeze. These allocations are assumed to be short-lived and frequently accessed.
Kernel Mode Backstop
This paper also describes a kernel component which complements the user space policy described so far. Whereas the user space code deals with allocations, the kernel code deals with pages. This is useful for allocations which do not access all pages uniformly. It is also useful for detecting and correcting suboptimal initial placements.
All PTEs associated with all allocations are continually scanned. The accessed bit determines if a page has been read since the last scan. The dirty bit determines if a page has been written since the last scan. After 10 scans, the system has a pretty good idea of how frequently a page is accessed. These statistics are used to migrate pages between fast and slow tiers.
Results
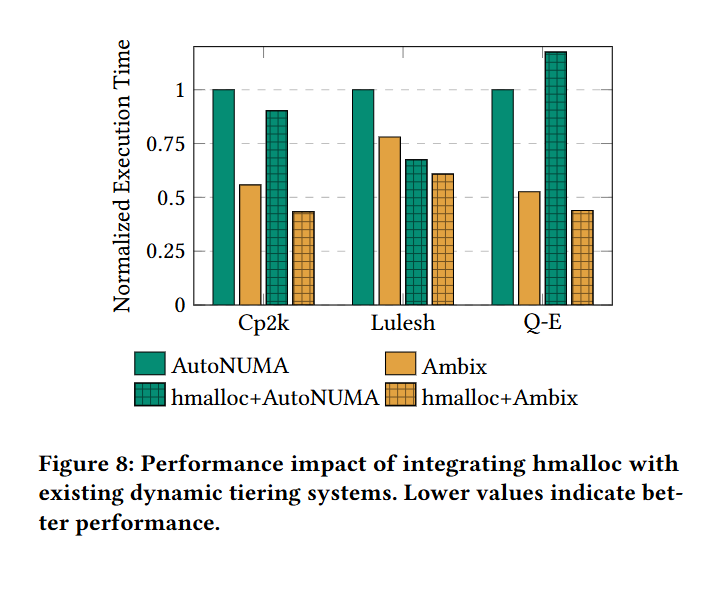
Fig. 8 shows execution time for three benchmarks. hmalloc+Ambix represents the user and kernel solutions described by this paper.
Dangling Pointers
I wasn’t able to find details in the paper about how PTE scanning works without interfering with other parts of the OS. For example, doesn’t the OS use the dirty bit to determine if it needs to write pages back to disk? I assume the PTE scanning described in this paper must reset the dirty bit on each scan.
The definition of an allocation context seems ripe for optimization. I suspect that allowing some variability in call stack or allocation size would allow for better statistics. Maybe this is a good use case for machine learning?
The allocation size is part of what determines the context?