
Binary Compatible Critical Section Delegation
A sneak way to ship code to data

Binary Compatible Critical Section Delegation Junyao Zhang, Zhuo Wang, and Zhe Zhou PPoPP'26
The futex design works great when contention is low but leaves much to be desired when contention is high. I generally think that algorithms should be crafted to avoid high lock contention, but this paper offers a contrarian approach that improves performance without code changes.
Contention Costs
Acquiring a futex involves atomic operations on the cache lines that contain the futex state. In the case of high contention, these cache lines violently bounce between cores. Also, user space code will eventually give up trying to acquire a lock the easy way and will call into the kernel, which has its own synchronization to protect the shared data structures that manage the queue of threads waiting to acquire the lock.
The problems don’t end when a lock is finally acquired. A typical futex guards some specific application data. The cache lines containing that data will also uncomfortably bounce between cores.
Delegation
The idea behind delegation is to replace the queue of pending threads with a queue of pending operations. An operation comprises the code that will be executed under the lock, and the associated data.
This C++ code snippet shows how I think of delegation:
// Typical locking
uint32_t x = 3;
mutex.lock();
shared_counter += x;
mutex.unlock();
// Delegation
uint32_t x = 3;
auto fn = [x, &shared_counter]()
{
shared_counter += x;
};
mutex.delegate(fn); // returns after `fn` is executed by _some_ threadIn the uncontended case, mutex.delegate will execute fn directly. In the contended case, fn will be placed into a queue to be executed later. After any thread finishes executing a function like fn, that thread will check the queue. If the queue is not empty, that thread will go ahead and execute all of the functions contained in the queue.
In the example above, the data guarded by the lock is shared_counter. If a particular thread calls 10 functions from the queue, then shared_counter remains local to the core that thread is running on, and the system will avoid moving shared_counter between cores 10 times.
Automatic Delegation
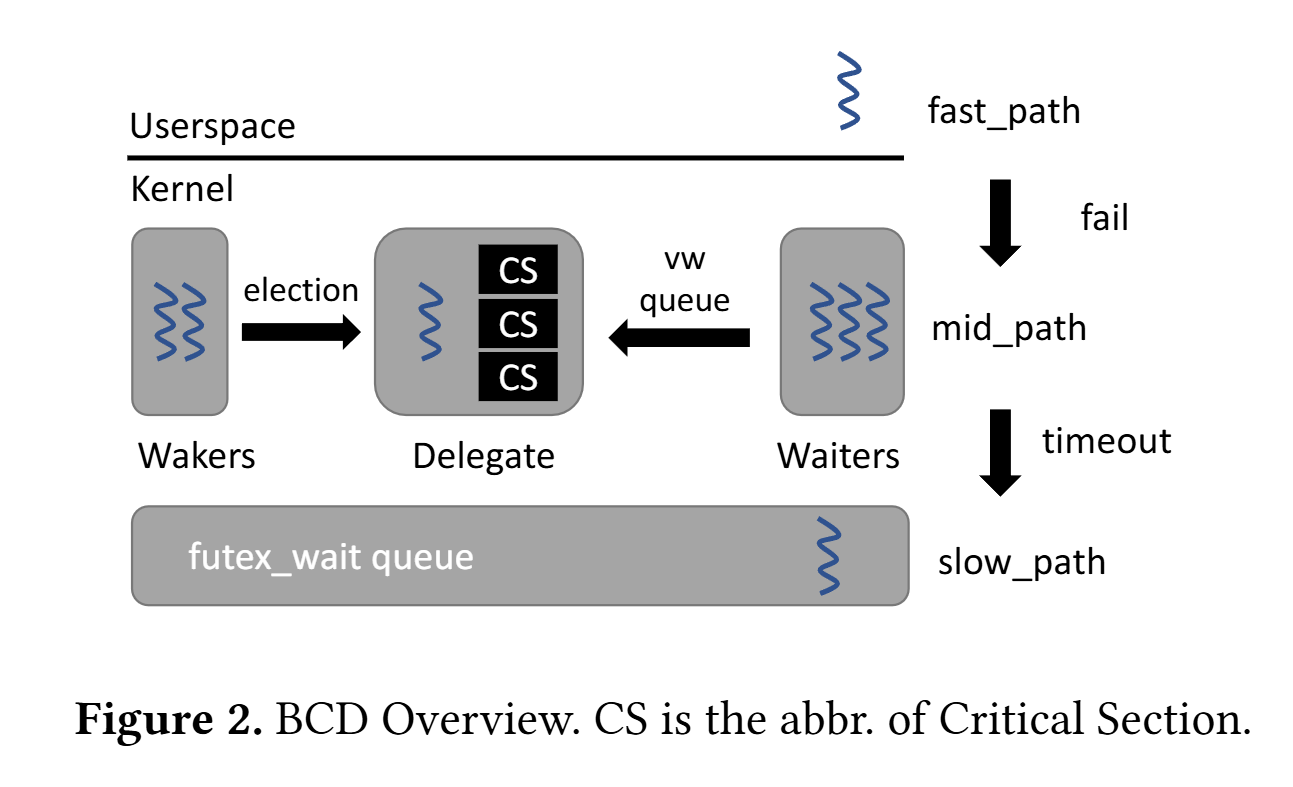
The magic of this paper is that it shows how to change the OS kernel to automatically implement delegation for any application that uses futexes. When the futex code gives up trying to acquire a futex in user space, it calls the OS to wait on the futex. The implementation of this system call is changed to implement automatic delegation. Automatic delegation can fail (as illustrated by Fig. 2), in which case the traditional futex waiting algorithm is used.
This paper makes heavy use of the Userspace Bypass library (a.k.a. UB; paper here). This library allows the kernel to safely execute user-mode code. It was originally designed to optimize syscall heavy applications, by allowing the kernel to execute the small tidbits of user space code in-between system calls. UB uses binary translation to translate instructions that were meant to run in user space into instructions that can securely be executed by the kernel.
Binary compatible critical section delegation uses UB to translate the code inside of the critical section (i.e., the code between the futex lock and unlock calls) into code that can be safely executed by the kernel. A pointer to this translated code is placed into a queue of delegated calls (the vw queue). The set of threads which are trying to acquire a lock cooperatively execute the functions in the vw queue. At any one time, at most one thread is elected to be the delegate thread. It drains the vw queue by executing (in kernel space) all the delegated functions in the queue. This works great in cases where the code inside of the critical section accesses a lot of shared state, because that shared state can happily reside in the cache of the core that is running the delegate thread, rather than bouncing between cores.
Results
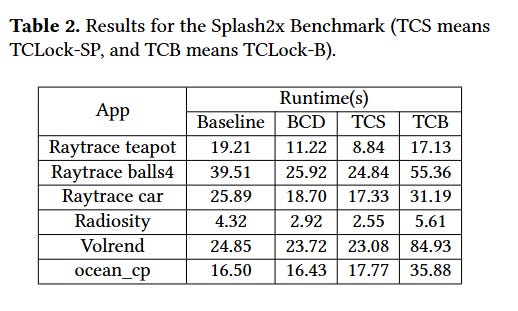
The paper has impressive results from microbenchmarks, but I think real applications are more relevant. Table 2 shows performance results for a few applications and a few locking strategies. BCD is the work in this paper. TCS and TCB are prior work which have the drawback of not being compatible with existing binaries.
Dangling Pointers
There is a hint here at another advantage of pipeline parallelism over data parallelism: allowing persistent data structures to remain local to a core.