
Cacheman: A Comprehensive Last-Level Cache Management System for Multi-tenant Clouds
Your L3 is more configurable than you thought

Cacheman: A Comprehensive Last-Level Cache Management System for Multi-tenant Clouds
I learned a lot about the LLC configuration and monitoring capabilities of modern CPUs from this paper, I bet you will too.
Shared L3 in the Cloud
The problem this paper addresses is: how to avoid performance variability in cloud applications due to cross-VM contention for the last level cache (e.g., the L3 cache on a Xeon)? In a typical CPU, the L1 and L2 caches are private to a core, but the L3 is shared. In a cloud environment, the L3 is shared by multiple tenants, and is an avenue for a “noisy neighbor” to annoy its neighbors.
CAT and CMT
The work described by this paper builds upon Intel CMT and CAT. Cache Monitoring Technology allows the hypervisor to track how much of the L3 cache is occupied by each VM. Cache Allocation Technology allows the hypervisor to restrict a VM to only use a subset of the L3.
CAT allows a VM to be assigned to a cache level of service (CLOS), which defines the set of L3 ways accessible to the VM (this page defines the term “ways” if you are unfamiliar). A typical CPU used by a cloud service provider has more CPU cores than L3 ways. If a cloud server hosts many small VMs, then L3 ways must be shared amongst VMs. The key problem solved by this paper is how to reduce performance variability given this constraint.
Gradient-Based Sharing
Fig. 1 illustrates the assignments of CLOS levels to LLC ways advocated by this paper. Each row is a level of service, and each column is a way of the LLC cache. CLOS[0] can access all ways, CLOS[1] can access all LLC ways except for one. CLOS[7] can only access a single way of the LLC.
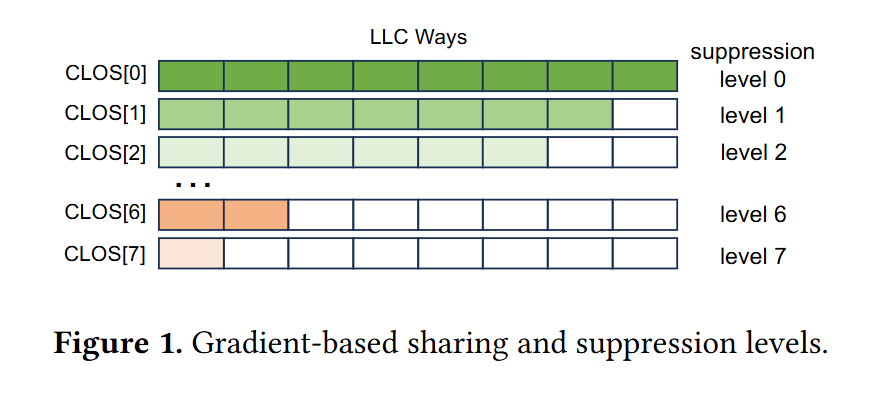
The hypervisor uses Intel CMT to monitor how much of the LLC is occupied by each VM. Every 6 seconds the hypervisor uses this information to change the CLOS that each VM is assigned to.
The hypervisor computes a target LLC occupancy for each VM based on the number of cores assigned to the VM. This target is compared against the measured LLC occupancy to classify each VM into one of three categories:
Poor (the VM is starved for space)
Adequate (the VM is using just the right amount of cache)
Excess (the VM is hogging too much)
VMs in the poor category are de-suppressed (i.e., assigned to a CLOS with access to more LLC ways). Additionally, VMs in the excess category are suppressed (i.e., assigned to a CLOS with access to fewer ways), but this suppression only occurs when there are VMs in the poor category.
This policy means that cache-hungry VMs can use more than their fair share of the L3 during periods of low server utilization. This can lead to higher mean performance, at the cost of a wider standard deviation. The paper describes a 4th state (overflow), which is only applied to VMs that wish to be held back even if there is plenty of L3 space available. These VMs are suppressed when they are found to be using too much L3, even if all other VMs on the system are getting enough cache space.
Results
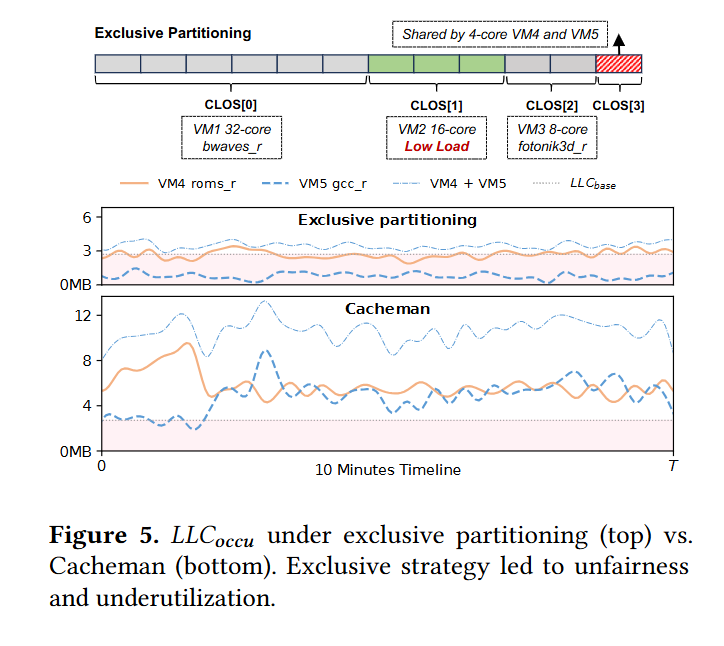
Fig. 5 shows a case where this strategy works well compared to static allocation. The server in question is running 5 VMs, each running a different application:
VM1 - 32 cores
VM2 - 16 cores (but doesn’t fully utilize those cores)
VM3 - 8 cores
VM4 - 4 cores
VM5 - 4 cores
The top of figure 5 shows a simple static partitioning of LLC ways. VM1 is assigned to 6 ways, VM2 is assigned to 3 ways, VM3 is assigned to 2 ways, and VMs 4 and 5 must share 1 way. They have to share because sharing based on the number of ways in the LLC is inherently coarse-grained.
The two charts show measured LLC utilization over 10 minutes. Notice the Y-axis. The technique described in this paper (Cacheman) allows VM4 and VM5 to use far more aggregate LLC capacity than the static partitioning. Also notice that in the static partitioning, VM5 always uses more LLC than VM4 (because they are running different applications), whereas Cacheman allows for a more even balance between them.
Dangling Pointers
While the L3 cache is logically a monolithic shared resource, it is physically partitioned across the chip (with a separate slice near each core). It seems like it could be more efficient if VMs could be assigned to nearby L3 slices rather than L3 ways.