
Disentangling the Dual Role of NIC Receive Rings

Disentangling the Dual Role of NIC Receive Rings Boris Pismenny, Adam Morrison, and Dan Tsafrir OSDI'25
DDIO
DDIO is a neat feature of Intel CPUs which causes the uncore to direct writes from I/O devices such that data lands in the LLC rather than main memory. In effect, the DDIO speculates that a CPU core will read the data before it is evicted from the LLC. This feature is transparent to the I/O device.
NIC Receive Rings
The paper describes a common HW/SW interface by which incoming network packets are sent from the NIC to the CPU. The key construct is a receive ring: a ring buffer where each entry is a pointer to an MTU-sized allocation in host memory. There is once receive ring per core. When the NIC receives a packet, it hashes fields from the packet header to determine which receive ring the packet should be placed in (Receive Side Scaling, a.k.a. RSS). The NIC then grabs a pointer into host memory from the ring, and issues DMA writes to the host to store the packet data at that location. There are head and tail pointers associated with the ring for the NIC and SW to use to avoid {under,over}flow.
Sounds simple enough, until you are the fool who has to choose the size of one of these receive rings. Such a halfwit must navigate the waters between a Scylla (Leaky DMA) and Charybdis (Load imbalance). If the aggregate size of all per-core rings is too large, then Leaky DMA sinks your ship. If any one ring is too small, then load imbalance strikes.
A key point to remember is that while the LLC is physically sharded among cores, it is logically shared by all cores.
Leaky DMA
If the sum total of all receive rings is too large, then the working set of the system no longer fits in the LLC. In this situation, when the NIC writes data for a packet into the LLC, it ends up inadvertently evicting data associated with an older packet. This defeats the whole purpose of DDIO.
Load Imbalance
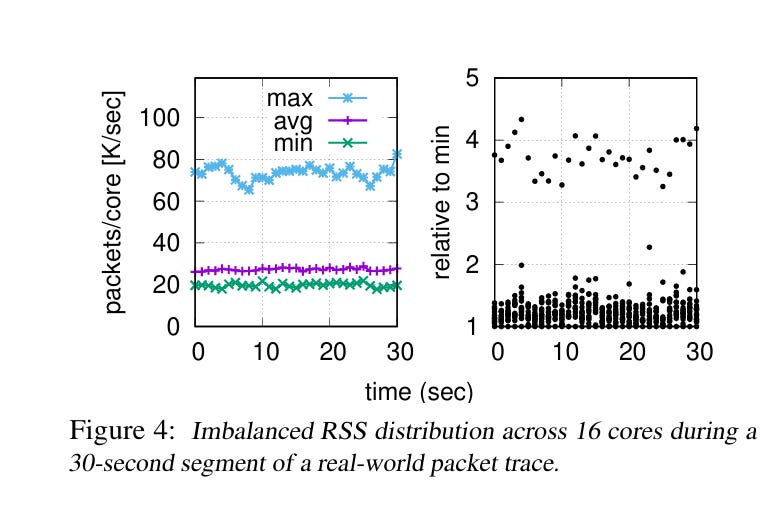
If the receive ring for any particular core is too small, and a burst of packets arrive for that core, then NIC will produce data faster than that core can consume it, and the NIC will be forced to drop packets. Fig. 4 presents evidence that this situation does occur in real life:
Decoupling
The solution presented by the paper is to decouple the ring such that the following parameters are made orthogonal:
Total amount of host memory available for the NIC to write packet data into, handled by the allocation (Ax) ring
Total number of packets that can be queued for processing by a specific core, handled by bisected reception (Bx) rings
The paper provides a general model; the simplest instantiation would be:
A single Ax ring for the whole system, sized so that the entire Ax ring fits in the LLC.
One Bx ring per core, each sized large enough to handle large bursts of packets all targeting one core
Leaky DMA is avoided because the Ax ring fits in the LLC. Load imbalance is avoided because each per-core ring is large enough to handle bursts. This configuration effectively dynamic shares the LLC between cores.
If incoming packets are evenly distributed among cores, then the LLC will be shared evenly between cores. In this situation, the Ax ring is the bottleneck (it might get close to empty), while Bx rings are lightly used. If there is a period of time where most packets are handled by a small number of cores, then those popular cores get a larger allocation of the LLC. In this case, the Bx rings of the popular cares are the bottleneck (they might get close to full).
One drawback of this approach can be noticed when a CPU core is done processing a packet. The MTU-sized allocation must be returned to the Ax ring for a future packet. If multiple cores can attempt to do this concurrently, then synchronization is needed, which could be costly.
The proposed solution in the paper is to have multiple Ax rings (e.g., one per core). Right after the NIC determines which core an incoming packet is destined for, it could attempt to grab an allocation from the Ax ring associated with that core. If that ring is empty, then the NIC could fall back to grabbing a packet from another Ax ring. This enables CPU cores to return packets to their dedicated Ax ring without synchronizing with other CPU cores.
Results
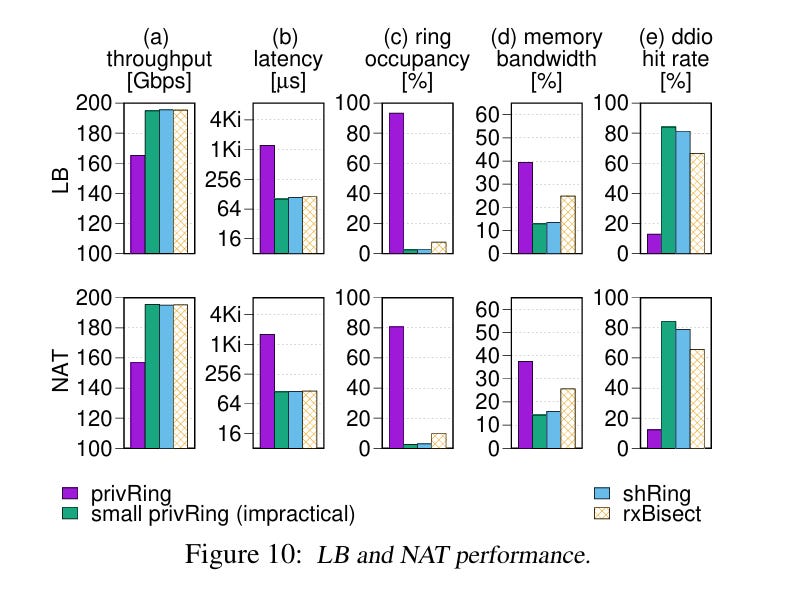
Fig. 10 has some great data. privRing is a baseline with large per-core rings, it suffers from leaky DMA. small privRing is a baseline with small per-core rings, it suffers from packet drops during bursts (not seen in this figure). shRing is prior work from the same authors, and rxBisect is the work in this paper.
Dangling Pointers
It would be interesting to see how the ideas proposed in the Necro-reaper paper could alleviate the leaky DMA problem. If SW running on the CPU could indicate to the LLC that it is done reading data for a specific packet, then there is no problem with that packet being “evicted” because it will not be written back to host memory.
Even if Scylla and Charybdis are avoided, I can’t help but feel sorry for the NoC in the host CPU. When packet data from the NIC destined for core 7 arrives, the host hashes physical addresses to determine which LLC partition to place the data into. Likely this DMA write data ends up in LLC partitions associated with cores other than core 7. When SW on core 7 goes to read this packet data, it must send requests to the LLC partitions associated with those cores to get the data. Given that the NIC knows which core is going to process the data, it is a shame it can’t control which LLC partition the data ends up in.
SCDI (from AMD) is an approach somewhat like DDIO. There are some key differences:
DMA writes from the I/O device are written to the L2 cache of a specific core
The I/O device must opt into this with TLP hints that indicate which core a DMA write is destined for
The authors collected data via an NIC emulator. An FPGA implementation would provide higher confidence performance numbers. It is a sad state of affairs that there isn’t an open-source FPGA NIC implementation that researchers can easily modify.
" It is a sad state of affairs that there isn’t an open-source FPGA NIC implementation that researchers can easily modify." I don't know if that was meant to be a sarcastic remark or not, but there are at least two of them: OpenNIC and Corundum
i'd love to know what do you think about CEIO, published in sigcomm '25