
Don't Repeat Yourself! Coarse-Grained Circuit Deduplication to Accelerate RTL Simulation

Don't Repeat Yourself! Coarse-Grained Circuit Deduplication to Accelerate RTL Simulation Haoyuan Wang, Thomas Nijssen, and Scott Beamer, ASPLOS'24
Poor Locality in RTL Simulation
Everyone who has spent time near hardware design knows that RTL simulators are slow. Few hardware designers know why, and most treat RTL simulators as a black box (e.g., most people don’t know how to change Verilog code to make it simulate faster). This paper helps shine a light in the darkness: one reason why RTL simulators are slow is that they have poor locality of data and/or instructions. This poor locality also means that you won’t get much traction by throwing cores at the problem. Even if you run totally independent simulations in parallel on the same machine, they will fight each other over the LLC.
An analogy to 3D graphics: a game engine typically renders each frame one after another. The amount of code and data required to render one frame exceeds the size of GPU caches, so there is no exploitable inter-frame locality. Imagine an artist and graphics engineer spent months perfecting some textures and shaders to render an octopus. When a child plays UnderSeaQuestUltra2 there is one octopus on a small fraction of the screen. On each frame, the GPU must load texture data and shader instructions required to render the octopus. By the time the next frame comes around, that data has been evicted from the cache.
A frame is to a graphics engine what a clock cycle is to an RTL simulator (full-cycle RTL simulators in particular). If an RTL simulator represents each piece of a hardware design with unique data stored in memory, then each piece of data will be read into the CPU data cache once per simulated clock cycle. Alternatively, if an RTL simulator compiles each piece of hardware design to unique CPU instructions, then each instruction will be read into the CPU instruction cache once per simulated clock cycle.
Unelaborated Simulation
A reasonable objection to the reasoning above is that hardware designs typically contain module reuse. For example, adder.v could define an Adder module which is instantiated 100 times in a design. Then a simulator could amortize the cost of reading data and/or instructions into CPU caches over those 100 instances. This would be analogous to a frame containing 100 octopuses, all of which share code and data.
There are a few problems with this approach:
Module instances can have different parameter values. For example, a 16-bit-wide adder and a 64-bit-wide adder may need different data or instructions to simulate correctly.
The inputs to different hardware instance maybe available at different times in a clock cycle. For example, imagine a chain of adders (where the output of one adder is the input to the next). These adders cannot all be simulated in parallel. [edit: see errata section for author feedback on this point]
The value of an output port on one module may affect the value of an input port of that same module (in the same clock cycle). The vocabulary here is a bit confusing. This output→input situation is called a cycle, but it is different than a clock cycle. The presence of output→input cycles means that the behavior of a single module instance within one clock cycle cannot be simulated in isolation. Fig. 4 (b) illustrates this.
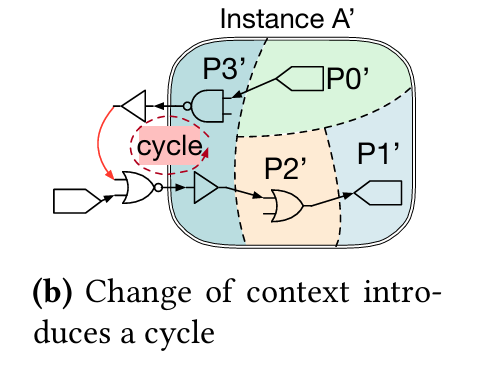
I’ve been a bystander to many (quasi-religious) debates about valid/ready signaling protocols at module boundaries, and if it is a good idea to mandate that neither the producer nor consumer “look at” the control signal generated by the other party until one clock cycle later. This paper is the evidence which indicates that EDA tools could have an easier time if all module I/O interfaces are registered.
Deduplication Partitioning
The solution described in this paper leans on existing acyclic partitioning support in the ESSENT simulator. ESSENT supports partitioning a hardware design into subgraphs in such a way that ensures that there are no inter-subgraph cycles (i.e., there is a topological sorting of partitions which provides a valid order in which partitions can be simulated within a clock cycle).
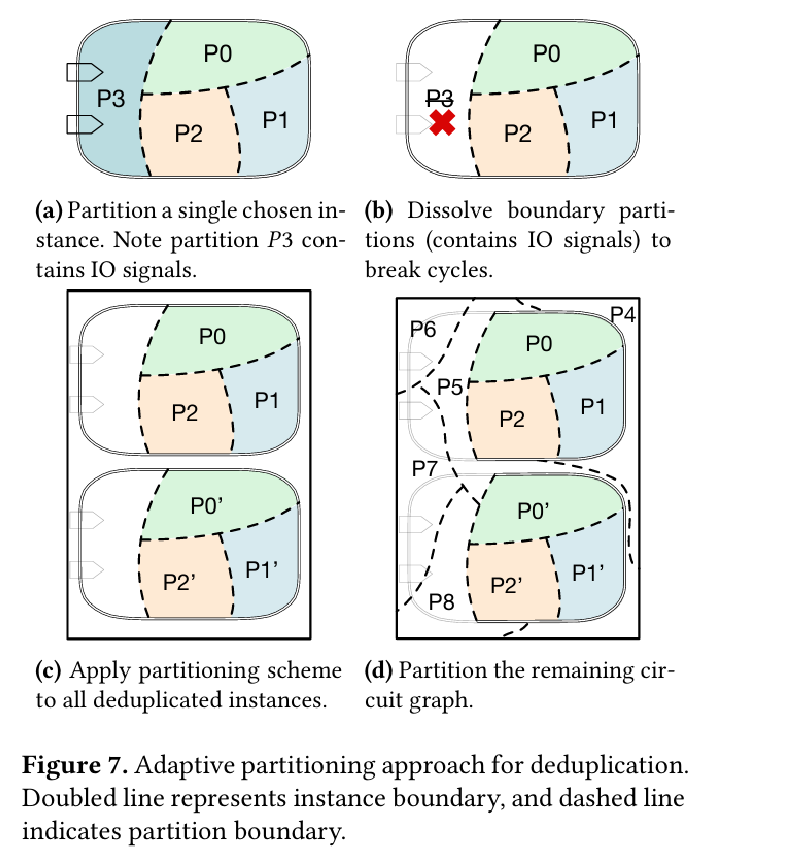
To support deduplication of module instances, a single module instance is partitioned, and then any partitions which touch the module I/O boundary are removed. The remaining are then de-duplicated across all module instances (i.e., each partition shares code with matching partitions in other module instances).
Fig. 7 illustrates this:
Scheduling
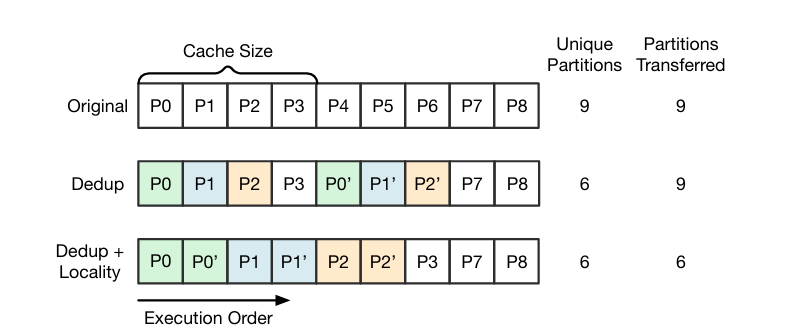
After deduplication, a topological sort is performed to determine a schedule for how the simulation will proceed within a simulated clock cycle. Fig. 5 illustrates an example schedule that has been optimized for locality:
Results
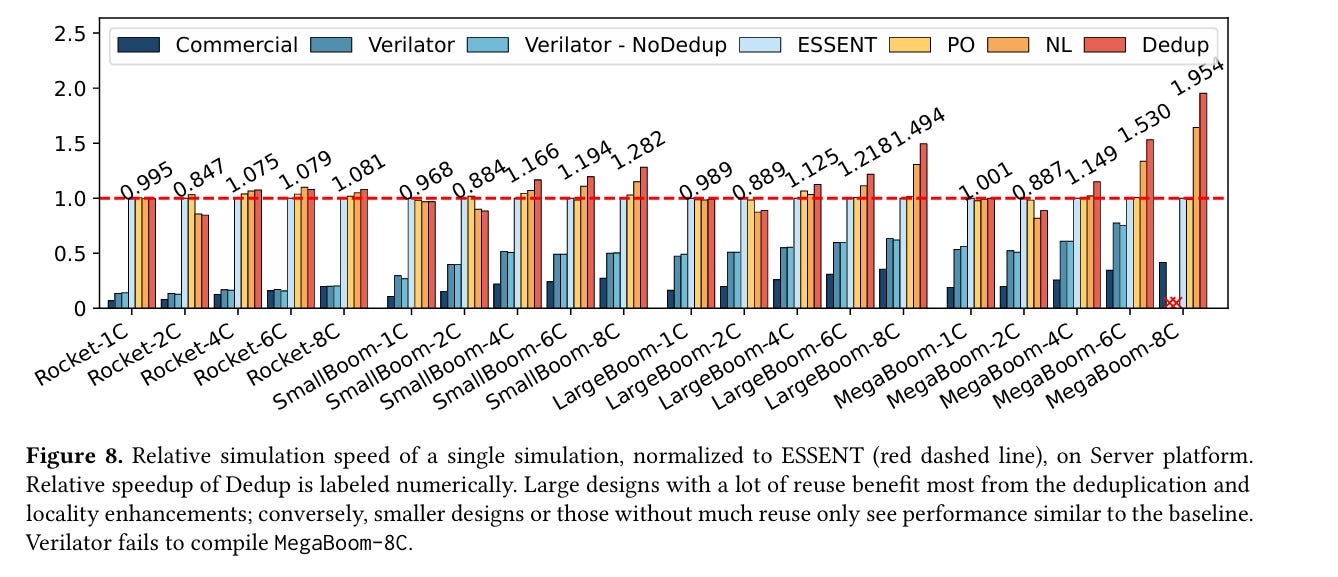
Fig. 8 shows simulation times for simulating different multi-core designs. This seems like a prime use case for deduplication: deduplicate whole cores. For these designs ESSENT already does pretty well compared to the alternatives. NL represents ESSENT extended to support deduplication across partitions. Dedup also includes support for modifying the simulation schedule to increase locality.
It makes sense to me that the case that would benefit the most is the most complex core design paired with the highest core count (MegaBoom-8C).
Dangling Pointers
De-duplicating module instances is practical, but it seems like there should exist algorithms which find sets of isomorphic sub-graphs within a larger graph.
Once the work has been done to deduplicate partitions, and schedule them so that they can execute back-to-back, it seems like a small step to simulate them with SIMD instructions (one instance per SIMD lane). [edit: see errata section for author feedback on this point]
Another way to improve locality of simulating a single module instance would be to simulate that instance in isolation over many clock cycles. For example, if all simulation state is known at clock cycle
N, then a given module instance could be simulated at clock cycleN+1,N+2,N+3. Inputs to the module would not be known for those future cycle. Speculation could be used to solve this, or some state elements (which are close to inputs) could be left as uncomputed until a later pass comes by and computes their values. I suspect that many real-world modules contain state elements which are far away from the input ports of the module (i.e., it takes many clock cycles for a change in input to affect the value of a such a state element). This seems like the same problem as optimizing stencil computations for cache locality (overview here).
Errata
An author sent me two pieces of feedback:
The primary concern with cycles is that they can cause an instance to be simulated multiple times per clock cycle.
In this work, entire simulations are run in parallel (rather than trying parallelize a single simulation as hinted at by dangling pointer #2).