
Efficient Lossless Compression of Scientific Floating-Point Data on CPUs and GPUs
A family of algorithms

Efficient Lossless Compression of Scientific Floating-Point Data on CPUs and GPUs Noushin Azami, Alex Fallin, and Martin Burtscher ASPLOS'25
This paper describes four (creatively named) lossless compression algorithms:
SPspeed: 32-bit floating-point, optimized for speed
DPspeed: 64-bit floating-point, optimized for speed
SPratio: 32-bit floating-point, optimized for compression ratio
DPratio: 64-bit floating-point, optimized for compression ratio
The claim to fame here is excellent performance on both CPUs and GPUs.
Building Blocks
Each compressor is implemented as a pipeline of transformations, illustrated in Fig. 1:
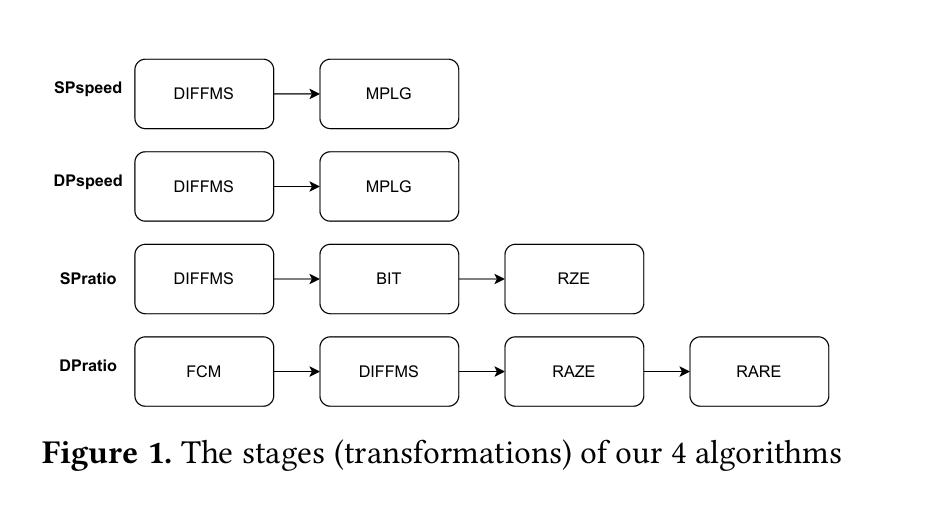
Decompression is similar, but the order of stages is reversed.
DIFFMS
The goal of DIFFMS is to transform the data such that most of the upper bits of each element to be compressed are 0. DIFFMS interprets inputs as integers (int32 or int64) and replaces element N with the difference between element N and element N-1. Differences are stored in sign-magnitude format. Neighboring values typically have small differences, so fewer bits are needed to store differences rather than raw values. Converting to sign-magnitude causes the upper bits of negative differences (which are close to zero) to be zero. The sign bit is stored in the least significant position, to ensure that it doesn’t contaminate the most-significant bit with a one.
The range of representable values in sign-magnitude format is one less than the range of values representable in two’s complement, but I suppose that is OK because that situation can only arise if an input float is NaN.
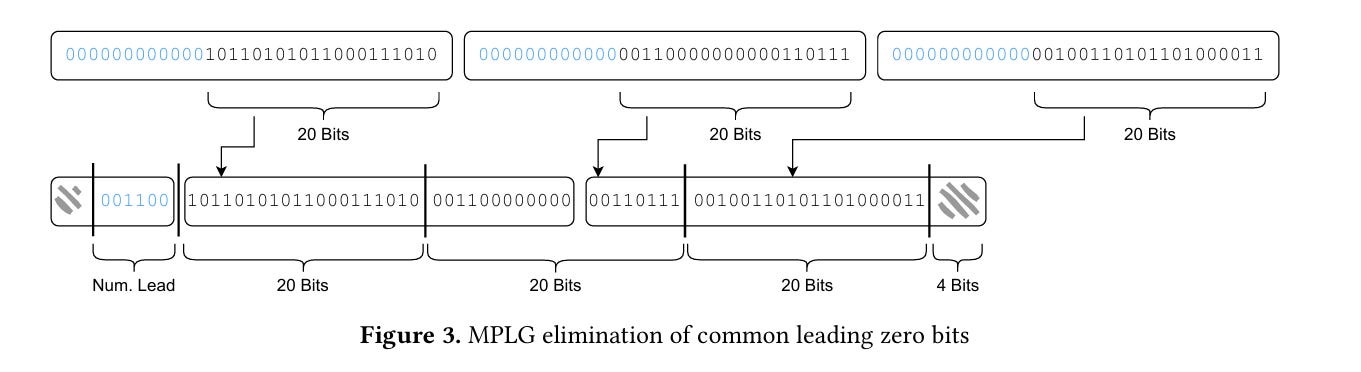
MPLG
Next, MPLG (introduced in a previous paper) operates on chunks of elements. For each chunk, MPLG finds the element with the highest-order non-zero bit and uses that to determine the number of leading bits which can safely be removed from each element in the chunk. This number of leading bits is stored in per-chunk metadata, and the input stream is bit-packed after removing those leading bits. Fig. 3 illustrates the bit packing:
BIT
The MPLG stage has the “one bad apple spoils the bunch” property. The BIT stage addresses that with a transpose. Each chunk is interpreted as a 2D array of bits, and that 2D array is transposed.
Say most elements in a chunk only require the least significant 8 bits, but one element requires 10 bits. Then after the MPLG stage, most elements will have 2 leading zeros in them. After the BIT stage, these zeros will all be grouped together rather than spaced apart.
Repeated Zero Elimination
After BIT has arranged the data such that there are many long ranges of zero bits in it, Repeated Zero Elimination (RZE) finds and removes bytes which are equal to zero. RZE produces both the output stream (with “zero bytes” removed), and a bitmap indicating which bytes were removed.
The authors found that RZE doesn’t work well for the low-order bits of double-precision data. They address this with RAZE and RARE, which do not try to eliminate ranges of zeros from the low-order bits.
Performance Characteristics
Each stage in the pipeline operates on chunks of data. The only interaction between chunks is that the size of the output data produced by chunk N is needed before the output offset of chunk N+1 is known. Efficient parallelization is possible in spite of this hazard on both CPU and GPU implementations.
As far as I can tell, there is no explicit attempt to ensure that the data passed between stages is kept on-chip. It could be that CPU and GPU caches work well enough for this purpose.
Results
These algorithms extend the Pareto frontier for both CPU and GPU.
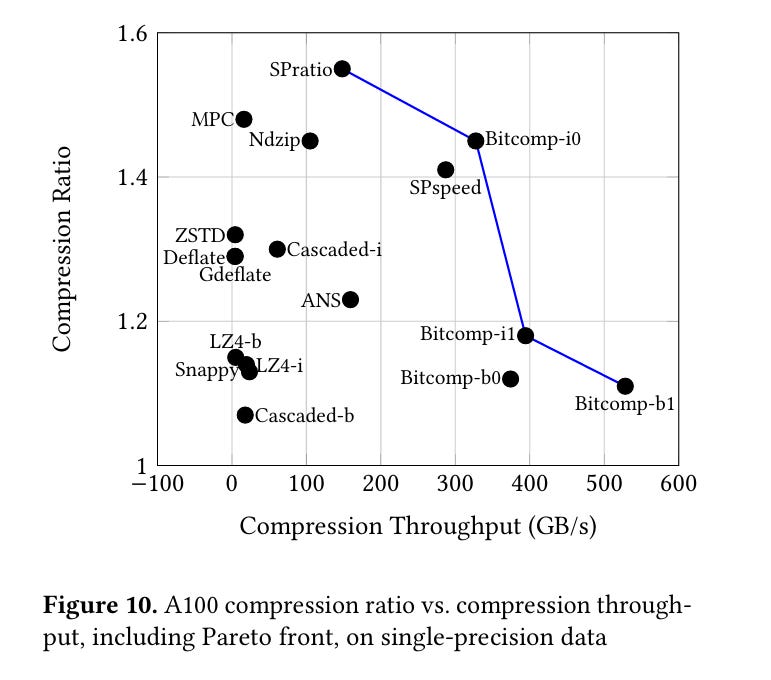
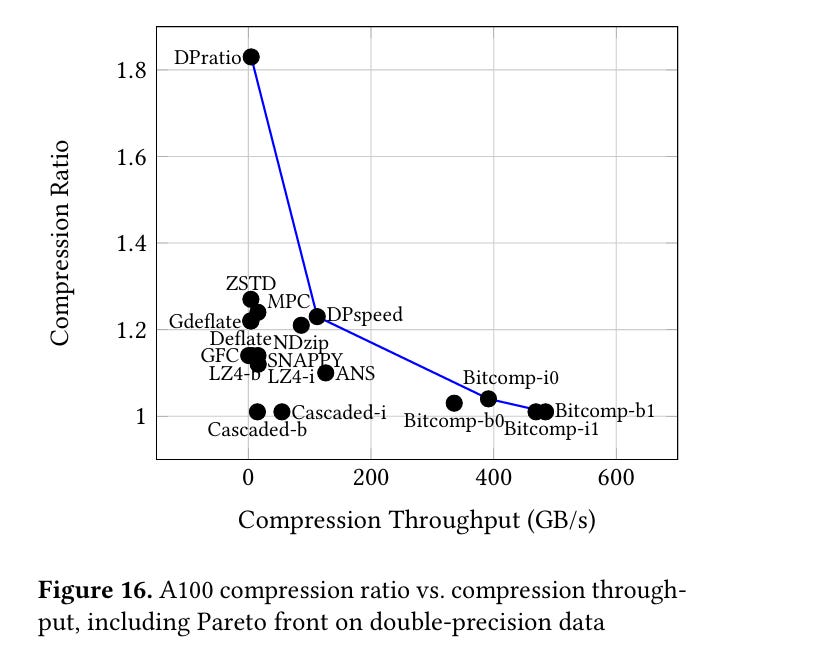
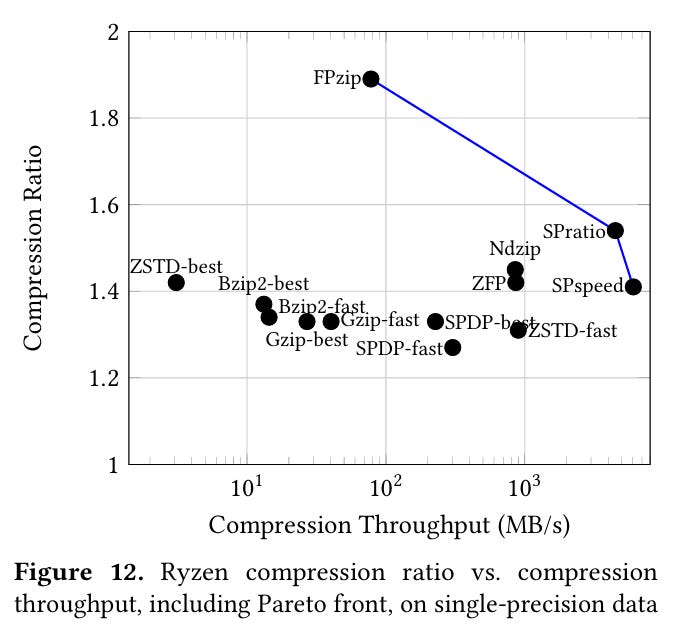
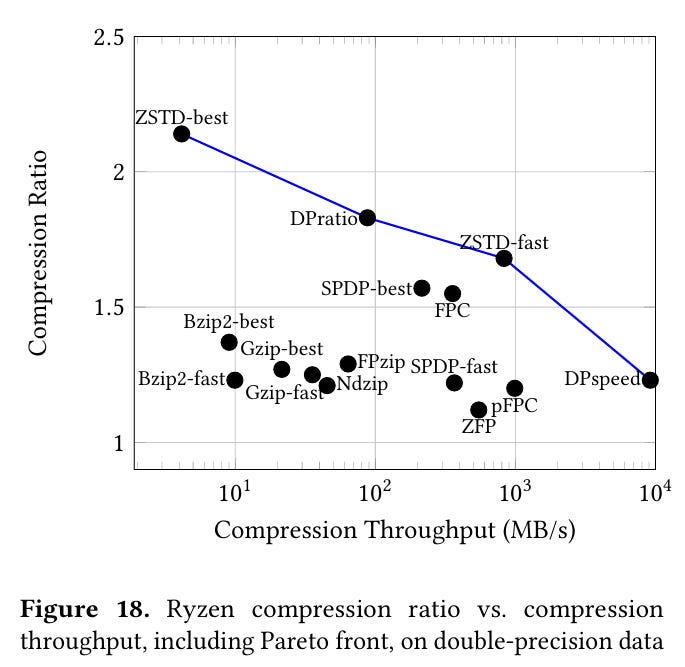
Dangling Pointers
The state of the art feels very hand-crafted, somewhat analogous to the state-of-the-art in image classification before AlexNet moved the state-of-the-art from handcrafted feature engineering to more generalized models. In the text compression space, LZ-based compressors leave the same aftertaste.