
Enabling Portable and High-Performance SmartNIC Programs with Alkali

Enabling Portable and High-Performance SmartNIC Programs with Alkali Jiaxin Lin, Zhiyuan Guo, Mihir Shah, Tao Ji, Yiying Zhang, Daehyeok Kim and Aditya Akella NSDI'25
SmartNIC HodgePodge
Fig. 1 illustrates four modern SmartNIC hardware architectures. Note the diversity of implementation options:
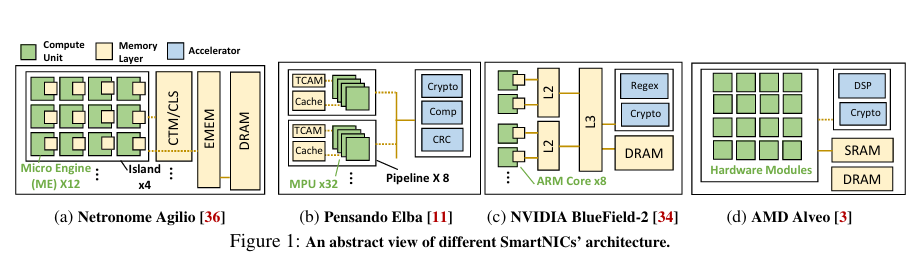
Woe to the engineer who must write high performance SmartNIC programs which are portable across these architectures. Alkali is a SmartNIC programming framework which enables high-performance SmartNIC programs to be written in a concise, portable way.
This paper classifies a SmartNIC based on the presence and configuration of three types of resources:
Compute
Memory
Reconfigurable match-action pipelines
The authors programming view #3 as a solved problem, and thus primarily focus on the first two resources.
Handler Graph
The Alkali framework is based on a compiler. It represents a SmartNIC program as a handler graph, where each edge in the graph runs inside of a single compute unit. A (single-threaded) user-written program is initially transformed into a simple handler graph. Then compiler optimization passes transform the graph so as to improve performance.
There are two primary ways that a handler graph can be optimized: replication and pipelining.
Replication
Replication allows multiple packets to be processed in parallel (across multiple compute units) by replicating handlers. An SMT solver is used to determine how many replicas of each handler should exist and assigns handlers to specific compute units. One input to the SMT solver is a performance model which is used to predict the amount of time a handler will spend processing each packet.
This transformation converts a single-threaded input program into a parallel one with shared-memory multi-threading. So, the question you should be asking yourself is: how can this be done correctly? Parallel access to shared data structures is only supported in two cases:
Accesses to read-only tables can be parallelized
Accesses to shardable tables can be parallelized (i.e., a table can be sharded across compute units)
Receive side scaling is an example of #2. Fields from a packet header are hashed together to produce an index, and that index is used to access a table. The table can be spread across compute units (e.g., compute unit 0 accesses half of the table while compute unit 1 accesses the other half). Packets are directed to the appropriate handler based on the computed index.
Pipelining
After replication, the compiler has an estimate of which handler is the bottleneck in the system. The compiler then attempts to split the handler into two, thus adding pipeline parallelism. A min-cut algorithm is used, which attempts to find a cut point that minimizes the amount of data that must flow between pipeline stages.
Just like replication, the pipelining process must be careful to not introduce correctness problems (i.e., concurrent access to a shared data structure from multiple pipeline stages). Before the min-cut algorithm is run, the compiler inserts synthetic vertices and edges into the graph corresponding to accesses to shared tables. For example, if a handler both reads and writes a table, then a vertex is added to the graph corresponding to the table, with bidirectional edges connecting the synthetic vertex to handlers which access the table. The edges have infinite weights, which prevents them from being cut.
Results
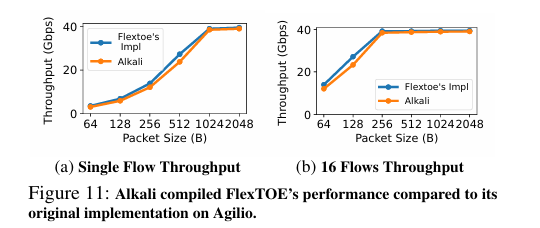
Fig. 11 has a performance comparison against an open-source implementation of a network transport. The pitch here is that Alkali offers abstraction and portability without sacrificing performance.
Dangling Pointers
The replication and pipelining process assumes that performance is predictable at compile time. Support for dynamic loops would invalidate this assumption, requiring profile-guided optimization or dynamic compilation.
The two supported shared-memory access patterns seem restrictive, it seems worthy to understand what other memory access patterns can be parallelized.
Section 9 of the paper mentions both of these limitations.
It is interesting that this framework is cast as SmartNIC-specific. Is there something special about networking that makes pipeline parallelism so attractive? I would think other domains could benefit from a similar framework.
Rather than a technical solution to SmartNIC programming, there might be an economic one. The early days of 3D graphics was a bit of a zoo, with separate programming frameworks for each hardware vendor. One thing that enabled Direct3D and OpenGL to succeed was industry consolidation. Over time, the market figured out which hardware approaches were best, and the industry converged. Once that convergence reached a certain point, then a portable platform became much easier to create. I wonder if SmartNIC programming simply needs time for the market to do its thing and create an ecosystem which is ripe for standardization.