
Forest: Access-aware GPU UVM Management
Plugging holes in a leaky abstraction

Forest: Access-aware GPU UVM Management Mao Lin, Yuan Feng, Guilherme Cox, and Hyeran Jeon ISCA'25
Unified Virtual Memory
Unified virtual memory is an abstraction which presents a single unified address space for both the CPU and GPU. This is a convenient programming model because it allows one device to create a complex data structure (with pointers) and pass that directly to the other device.
Maintaining this illusion in systems with discrete GPUs is a complex task. The state-of-the-art involves initially placing allocations in host memory and then copying them to GPU memory to resolve GPU page faults (far-faults). Prefetching can help avoid some far-faults. A state-of-the-art prefetcher is called the tree-based neighboring prefetcher (TBNp). Fig. 3 shows the TBNp data structure for a 512KiB allocation:
Tree-based Neighboring Prefetcher
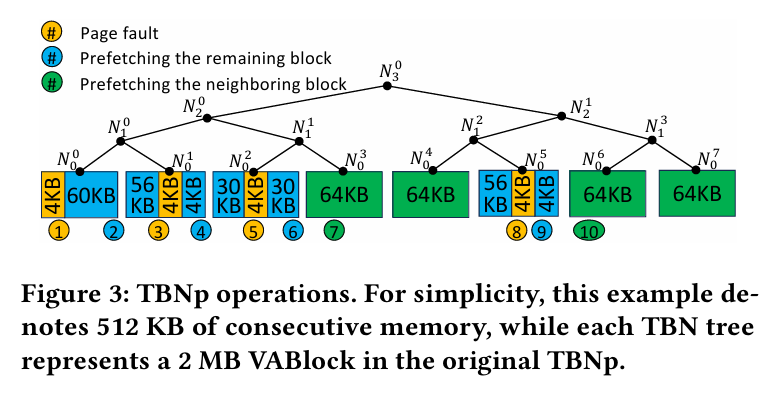
TBNp tracks each 2MiB of virtual memory with a binary tree containing 64KB leaf nodes. When a far-fault occurs on a 4 KiB page (yellow “1” in Fig. 3) the remaining 60 KiB (blue “2” in Fig. 3) in the leaf are prefetched.
Once the leaves contained by a particular sub-tree are >= 50% resident in GPU memory, the remainder of the sub-tree is prefetched. In Fig. 3 that situation occurs when the three left-most leaf nodes have been transferred to GPU memory. At that point, the remaining leaf node in the subtree (green “7” in Fig. 3) is prefetched.
Access Pattern Profiling
This paper proposes customizing the TBNp trees associated with each object, with the help of access pattern profiling hardware. Fig. 7 illustrates the design:
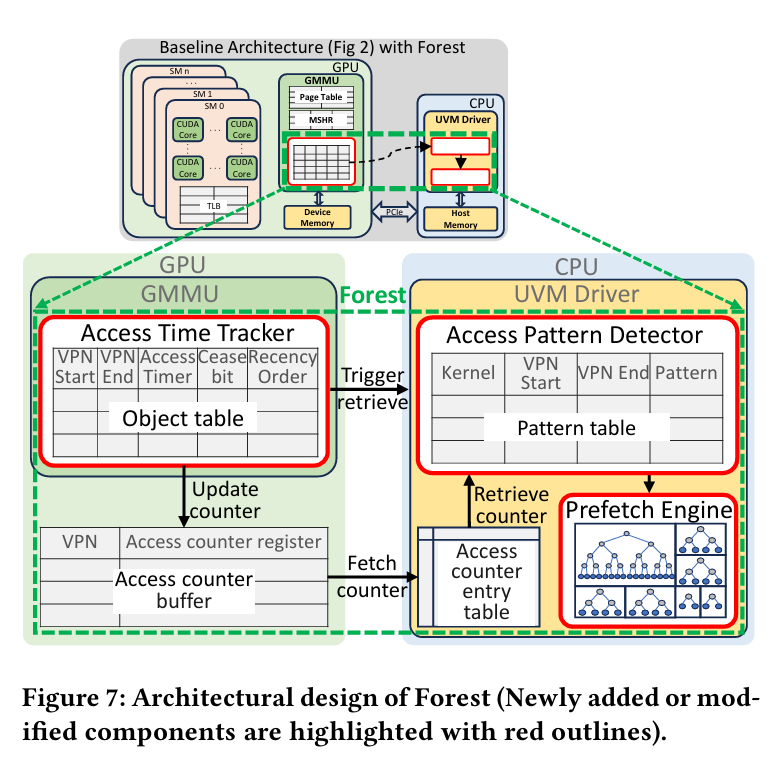
The GPU MMU tracks access times for each object (i.e., allocation created by cudaMallocManaged) and for each page. Once a healthy amount of profiling data has been collected, the GPU fires an interrupt which notifies the driver that it should grab the latest statistics.
Access Pattern Classification
The driver classifies access patterns for each object into one of the following four buckets:
Linear/Streaming
Non-Linear, High-Coverage, High-Intensity
Non-Linear, High-Coverage, Low-Intensity
Non-Linear, Low-Coverage
The paper uses tree-based prefetching like TBNp, but configures the trees differently for each object depending on the access pattern bucket. This is where the name “Forest” comes from: each tree has a maximum size, so large objects are chopped up and tracked with multiple trees.
Streaming accesses are detected with linear regression. If the R2 value is close to 1, then the driver classifies the accesses as streaming. The prefetching trees used for objects accessed in a streaming manner are 4MiB in size and contain 256KiB leaf nodes (relatively large).
If the driver determines accesses are not streaming, then the choice between the remaining three buckets is determined by the access coverage and access intensity. Access coverage is computed based on the minimum and maximum page numbers accessed during profiling. Access intensity is based on the number of accesses during profiling.
For objects with high access coverage and high access intensity, the associated prefetching trees are 512KiB in size and contain 64KiB leaf nodes.
For objects with high access coverage and low access intensity, the associated prefetching trees are 512KiB in size and contain 16KiB leaf nodes.
Finally, for objects with low access intensity, the associated prefetching trees are 2MiB in size and contain 64KiB leaf nodes.
Results
Fig. 12 contains simulation results for a number of benchmarks:
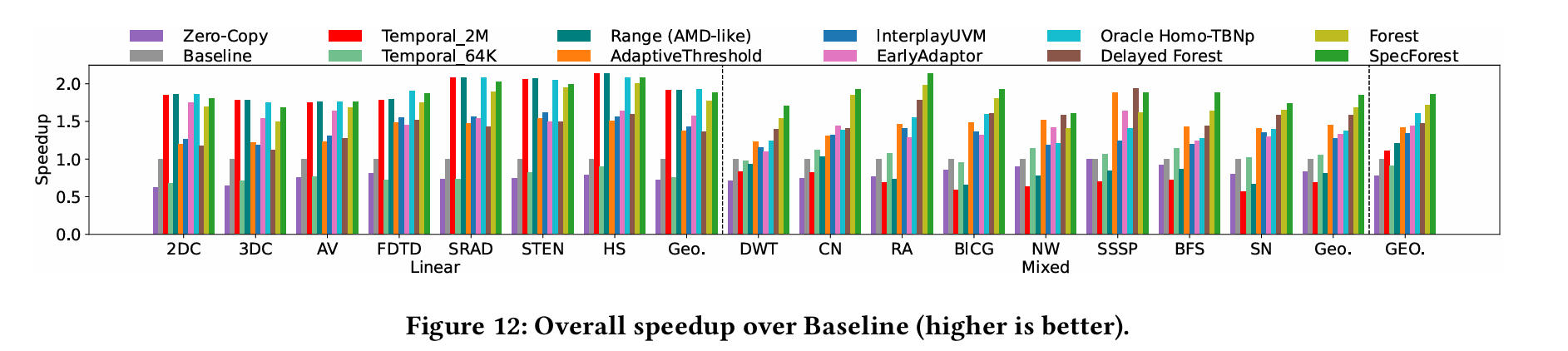
Forest is the design described in this paper. SpecForest is a modification that avoids the overheads associated with initial profiling by trying to make better initial guesses about access patterns before profiling data is available.
Dangling Pointers
I wonder how much vertical integration can help here. Certainly, a number of applications have enough context to make smarter decisions than the driver relying on profiling information.