
Iso: Request-Private Garbage Collection

Iso: Request-Private Garbage Collection Tianle Qiu and Stephen M. Blackburn PLDI'25
Fragile Garbage Collection Costs
I’ve seen something like this before:
The benchmark has a quirk: if the heap is sized just right, then the cost of GC plummets unexpectedly to near zero. If the heap is made slightly smaller or slightly larger, the GC cost will return to a significant level.
This situation applies to applications which allocate memory in waves. For example, a compiler implemented as a series of passes (each of which transforms the IR) may have a large working set when it is in the middle of pass execution, but a low working set in-between passes. Or a (single-threaded) server may have a large working set when processing a request, and a low working set in-between requests. If the cost of garbage collection is proportional to the number of live objects, then it pays to trigger garbage collections when the number of live objects is at a local minimum.
There is no obvious way to implement such a scheme in a shared-memory multi-threading environment. Say you have a process with 8 threads, each of which processes requests serially. The working set of each thread will have a wavelike pattern, but the working set of the whole system will not. One could artificially add synchronization between the threads to remove this destructive interference, but that would degrade throughput and increase tail latency. One could have separate memory spaces (and garbage collection instances) for each thread, but that would preclude sharing of data between threads. It would be equivalent to running each thread in a separate process, which presumably would have a negative impact on performance.
This paper describes a “have your cake and eat it too situation”. The application code can mostly remain unmodified, and a special garbage collector can be used which optimized this use case. The garbage collector is named Iso.
Private and Public Objects
Iso categorizes each allocated object as private or public. Private objects can only be referenced (directly or indirectly) by the stack of the thread which allocated them. All other objects are public. Static analysis could be used to determine if some objects are known to be public or private at compile time. Otherwise, this information can be tracked dynamically. Freshly allocated objects start out as private, but they may be promoted to public later on. This private→public promotion is called publishing.
The application logic (executed by mutator threads) is instrumented with a write barrier. The write barrier logic runs when a pointer field is modified, and it is used to detect when a private object is made referenceable from a public object (the time when the private object must be published). Listing 1 shows the write barrier code:

Garbage Collector Blocks
The memory managed by the garbage collector is divided into 32KiB blocks (each block is divided into 256B lines). A block can contain public objects, and it can also contain private objects. A public block only contains public objects. A private block only contains private objects. A mixed block contains both private and public objects. However, a mixed block can only contain private objects associated with one thread. This is called the Block invariant.
Publishing an object is lightweight. The object can stay where it is. If an object in a private block is published, then that block becomes a mixed block.
Iso maintains lists of (completely or partially free) blocks which are used to satisfy allocations. There is a global list, and there are thread-private lists. When a thread needs a block to satisfy an allocation, it first searches in its private list. If no block is found there, then the thread consumes a block from the global list (converting a public block into a mixed block).
Local Garbage Collection
Local garbage collection is responsible for finding and freeing private objects. The assumption is that most objects are private, and garbage collection of private objects can reliably take advantage of the fact that garbage collection is fast when performed at the trough of a private wave.
The paper suggests that application code can be modified to trigger a local GC in between requests. A size threshold can be used otherwise.
Local garbage collection marks all private objects which are reachable from the local thread stack. Then there is a sweep over all private and mixed blocks associated with the thread. Any private object contained in those blocks which was not marked (i.e., is garbage) is freed (by marking the associated lines as free). This process can convert blocks from mixed→public.
Local garbage collection can also perform local defragmentation by moving private objects.
Global Garbage Collection
Global garbage collection is responsible for freeing public objects. A standard garbage collector (Immix) is used. Global garbage collection is heavyweight and requires synchronizing threads. The assumption is that global garbage collection does not need to run frequently, because most objects are private.
Global garbage collection can perform global defragmentation by moving global objects.
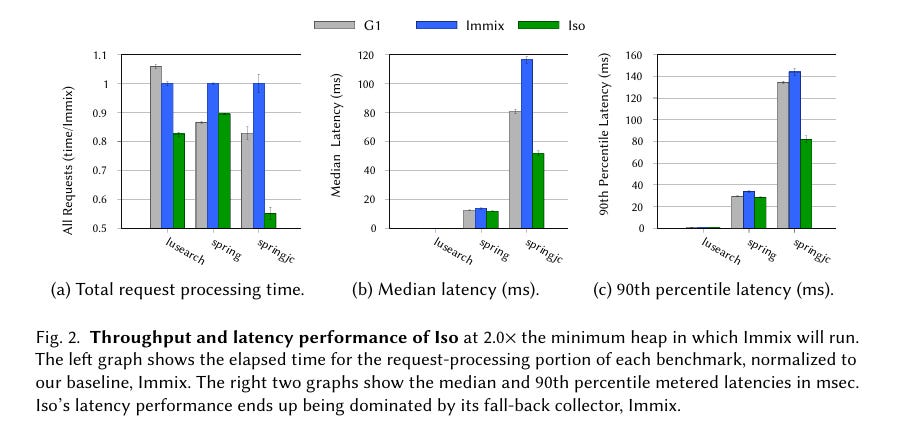
Results
Fig. 2 shows some promising results but notes that the global garbage collector is still very present in the latency numbers.
Dangling Pointers
The public/private categorization seems like a specialized instance of a more general framework. If complexity can be tolerated in application code, then I think more structure is possible. Applications could specify many categories of allocations, the inter-category relationships, and the relationship between threads and categories. For example, there could be a category of allocations which is only ever visible to 2 specific threads.