
Necro-reaper: Pruning away Dead Memory Traffic in Warehouse-Scale Computers

Necro-reaper: Pruning away Dead Memory Traffic in Warehouse-Scale Computers Sotiris Apostolakis, Chris Kennelly, Xinliang David Li, and Parthasarathy Ranganathan ASPLOS'24
Memory Bandwidth Bottleneck
In the good old days, the only practical way to saturate DRAM bandwidth from a CPU was to run an algorithm with very low arithmetic intensity (e.g., memcpy or memset). In modern times, core counts have been growing faster than DRAM bandwidth. This With each passing year, it becomes easier for the aggregate DRAM traffic from all CPU cores to saturate DRAM bandwidth. This is a problem in many environments. The vertical integration in warehouse-scale computing (WSC) enables optimizations which are infeasible in other domains.
Dead Fetch-on-Miss
A dead fetch-on-miss occurs when a cache line is fetched from DRAM to service a cache miss, and the fetched line contains deallocated data (i.e., data that will not affect the computation). Necro-reaper’s solution to avoid these unnecessary DRAM reads is a new ARM ISA instruction: DC IZVA. This instruction acts like a cache miss but sets all bits of the cache line to zero rather than fetching them from DRAM. The paper calls this installation.
The ARM ISA already defines a similar instruction: DC ZVA, the behavioral difference happens when such a cache line is evicted before any data has been written to it. With the existing DC ZVA instruction, the zeros are written back to DRAM. With the proposed DC IZVA, nothing is written back. Another way of thinking about this is that the existing instruction can be used for initializing an object to 0, while the Necro-reaper approach is to leave the initialization code in the application logic.
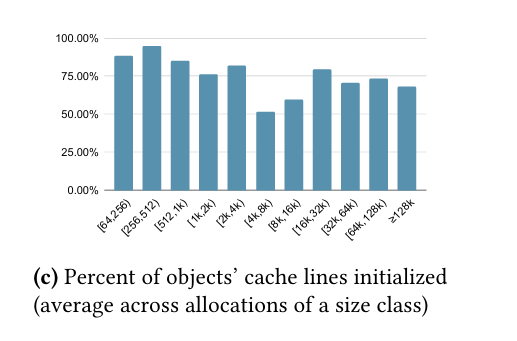
Necro-reaper modifies the memory allocator to install cache lines immediately after allocation. The paper includes a lot of data and discussion about allocations which are not fully used. For example, 1KiB of memory could be allocated, but then only 768 bytes are actually touched. Necro-reaper uses profile guided optimization (PGO) to address this. PGO runs produce per-allocation-site statistics which are used to determine how much of an allocation to install. If no PGO statistics are available, then 75% of the allocation is installed. Fig. 4c motivates this heuristic:
Dead Writeback
Dead writeback occurs when a cache line is evicted from the CPU cache (written back to DRAM), and that data is never used again. For example, an allocation could be freed back to the heap, and then later the associated cache lines could be evicted (wasting DRAM bandwidth in the process). Necro-reaper proposes to solve this with the existing DC IVAC ARM instruction. This instruction invalidates a cache line, which will prevent it from being written back to DRAM on eviction. One hitch is that the instruction currently can only be executed by the hypervisor/kernel. Section 4.3.3 describes how to mitigate security issues associated with letting applications use this instruction.
A potential pitfall with this approach is frequent unnecessary invalidations (the cache line will be written again before it is evicted). One reason why this is a problem is that invalidations generate cache coherency traffic. Necro-reaper again proposes PGO to address this.
PGO for invalidation is not application specific, but rather memory allocator specific. For example, when using a size-class-based allocator like TCMalloc, certain size classes may show frequent reuse, while others may not. PGO statistics are used to help the compiler to decide when to invalidate after deallocation, based on the size of the deallocated object.
Results
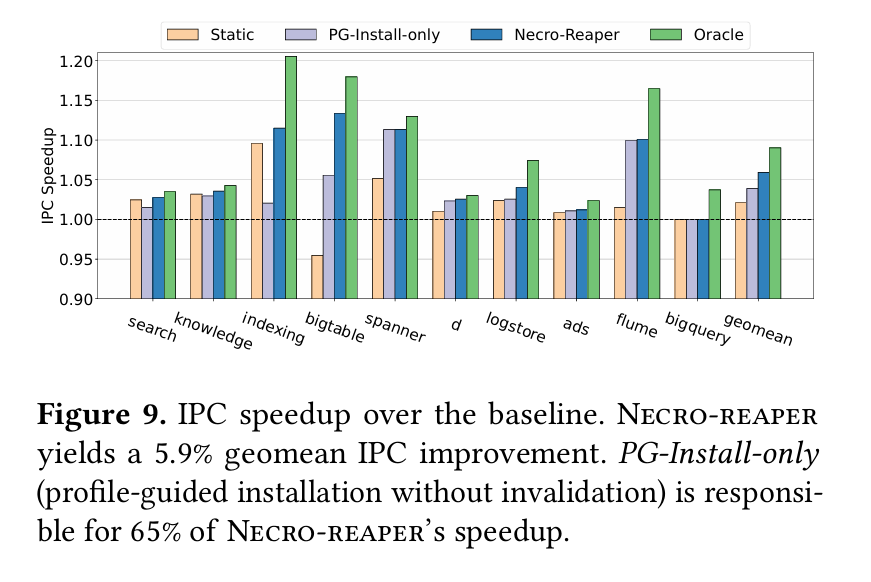
A 5.9% improvement in IPC, which I assume is a big deal for Google:
Dangling Pointers
The reason this makes sense for WSC (e.g., hyperscalars) are economic. Vertical integration makes PGO (collecting statistics, and then re-compiling everything based on those statistics) possible. Large scale deployments means that a 5.9% speedup is significant and worth spending significant resources on.
I can’t help but wonder if the unspoken assumption is that significant modifications to the CPU microarchitecture are off the table. For example, if a CPU designer wanted to solve these problems in isolation, I imagine they could come up with a lazy fetch scheme to eliminate dead fetch-on-misses. Similarly, I think a lazy invalidation instruction could be executed by a deallocation function unconditionally, and the CPU could actually do the invalidation work (send coherence messages) at some later point, if the cache line was not written in the meantime.