
Optimizing Datalog for the GPU
Datalog primer and a neat data structure

Optimizing Datalog for the GPU Yihao Sun, Ahmedur Rahman Shovon, Thomas Gilray, Sidharth Kumar, and Kristopher Micinski ASPLOS'25
Datalog Primer
Datalog source code comprises a set of relations, and a set of rules.
A relation can be explicitly defined with a set of tuples. A running example in the paper is to define a graph with a relation named edge:
Edge(0, 1)
Edge(1, 3)
Edge(0, 2)A relation can also be implicitly defined with a set of rules. The paper uses the Same Generation (SG) relation as an example:
1: SG(x, y) <- Edge(p, x), Edge(p, y), x != y
2: SG(x, y) <- Edge(a, x), SG(a, b), Edge(b, y), x != yRule 1 states that two vertices (x and y) are part of the same generation if they both share a common ancestor (p), and they are not actually the same vertex (x != y).
Rule 2 states that two vertices (x and y) are part of the same generation if they have ancestors (a and b) from the same generation.
“Running a Datalog program” entails evaluating all rules until a fixed point is reached (no more tuples are added).
Semi-naïve Evaluation
One key idea to internalize is that evaluating a Datalog rule is equivalent to performing a SQL join. For example, rule 1 is equivalent to joining the Edge relation with itself, using p as the join key, and (x != y) as a filter.
Semi-naïve Evaluation is an algorithm for performing these joins until convergence, while not wasting too much effort on redundant work. The tuples in a relation are put into three buckets:
new: holds tuples that were discovered on the current iterationdelta:holds tuples which were added in the previous iterationfull: holds all tuples that have been found in any iteration
For a join involving two relations (A and B), new is computed as the union of the result of 3 joins:
delta(A)joined withfull(B)full(A)joined withdelta(B)delta(A)joined withdelta(B)
The key fact for performance is that full(A) is never joined with full(B).
More details on Semi-naïve Evaluation can be found in these notes.
Hash-Indexed Sorted Array
This paper introduces the hash-indexed sorted array for storing relations while executing Semi-naïve Evaluation on a GPU. It seems to me like this data structure would work well on other chips too. Fig. 2 illustrates the data structure (join keys are in red):
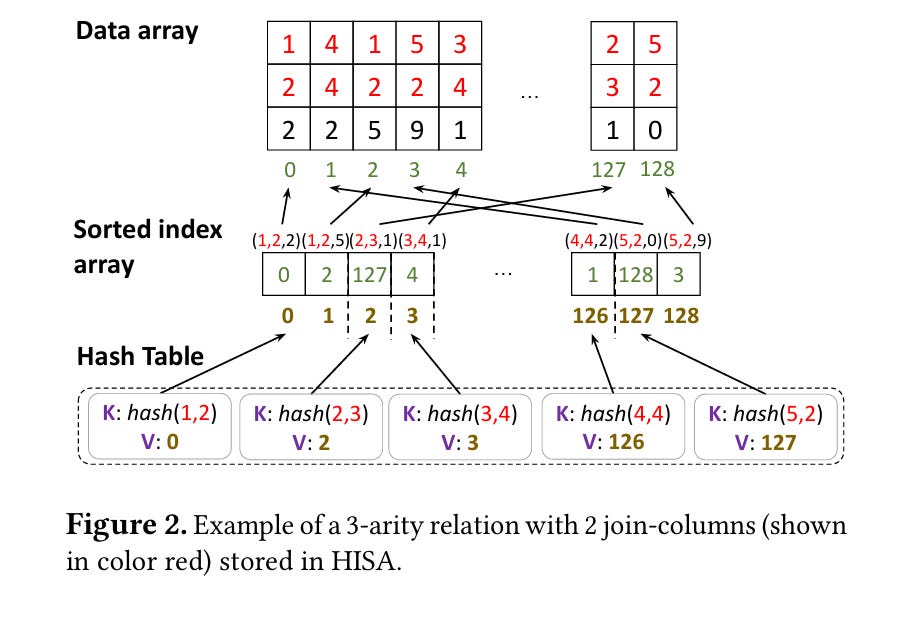
The data array holds the actual tuple data. It is densely packed in row-major order.
The sorted index array holds pointers into the data array (one pointer per tuple). These pointers are lexicographically sorted (join keys take higher priority in the sort).
The hash table is an open-addressed hash table which maps a hash of the join keys to the first element in the sorted index array that contains those join keys.
A join of relations A and B, can be implemented with the following pseudo-code:
for each tuple 'a' in the sorted index array of A:
lookup (hash table) the first tuple in B which has matching join keys to 'a'
iterate over all tuples in the sorted index array of B with matching keysMemory accesses when probing through the sorted index array are coherent. Memory accesses when accessing the data array are coherent up to the number of elements in a tuple.
Results
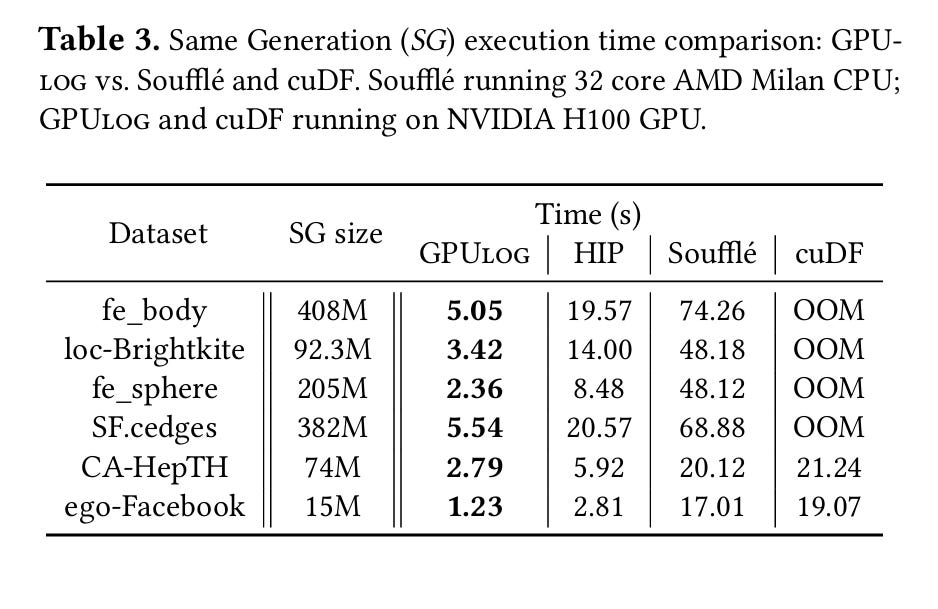
Table 3 compares the results from this paper (GPULog) against a state-of-the-art CPU implementation (Soufflé). HIP represents GPULog ported to AMD’s HIP runtime and then run on the same Nvidia GPU.
Dangling Pointers
The data structure and algorithms described by this paper seem generic, it would be interesting to see them run on other chips (FPGA, DPU, CPU, HPC cluster).
I would guess most of GPULog is bound by memory bandwidth, not compute. I wonder if there are Datalog-specific algorithms to reduce the bandwidth/compute ratio.
As a heavy Datalog user, here's my opinion of the paper.
Generally, my objection to this work would be that almost all "Datalog" programs they evaluate (7 programs in total) are either just SQL (i.e., they only have joins, no recursion) or they are transitive closure (i.e., they only have linear recursion). This is not Datalog. This is *provably* (one of the few things we can prove in complexity theory) a lower complexity class than Datalog. So, there is very strong reason to believe that these results do *not* translate to full Datalog. Transitive closure can be sped up arbitrarily much, compared to more complex recursion.
The authors only evaluate *one* program (out of the 7) that has complex recursion. That one is "context-sensitive program analysis" (CSPA). However:
a) the souffle version is not optimized for complex recursion, I strongly suspect it can be sped up by 2 orders of magnitude, so I really doubt the GPU speedup for this one
b) despite the name, the analysis is not "context-sensitive", but let's just say this is an oversight
c) it's still just a 10-line program, hardly representative of full Datalog.
Methodologically, I cannot reproduce anything from this paper, at least not without talking to the authors directly. The artifact link in the paper (https://file.io/YZE8MKx12iqX) is broken already. In the repo, most of the large inputs are replaced with git lfs links and the github repo doesn't seem to serve git lfs, e.g., https://github.com/harp-lab/gdlog/blob/main/data/cspa/httpd/assign.facts