
Predicate Transfer: Efficient Pre-Filtering on Multi-Join Queries

Predicate Transfer: Efficient Pre-Filtering on Multi-Join Queries Yifei Yang, Hangdong Zhao, Xiangyao Yu, Paraschos Koutris CIDR'24
The Joy of Filter Push Down
Here is query 5 from TPC-H (you can find it in the TPC-H spec here):
select
n_name,
sum(l_extendedprice * (1 - l_discount)) as revenue
from
customer,
orders,
lineitem,
supplier,
nation,
region
where
c_custkey = o_custkey
and l_orderkey = o_orderkey
and l_suppkey = s_suppkey
and c_nationkey = s_nationkey
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = '[REGION]'
and o_orderdate >= date '[DATE]'
and o_orderdate < date '[DATE]' + interval '1' year
group by
n_name
order by
revenue desc;A naive implementation of this query is: the select occurs first (producing a boatload of rows) and then the expressions within the where run subsequently, which cause many rows to be dropped.
A smarter implementation pushes-down the r_name and o_orderdate filter expressions such that the select doesn’t even see rows which would fail one of these tests. This is great because it effectively makes the region and order input tables much smaller (fewer rows), and so every downstream operator runs faster.
But how to do something similar for the other tables which don’t have an explicit filter (other than comparing join keys)? A bloom join can solve this for a join of two tables. For example, a bloom filter could be built when processing the orders table. If a row passes the explicit filter on o_orderdate, then the value in the o_orderkey column is inserted into the bloom filter. When the lineitem table is processed, the value in the l_orderkey is used to probe the bloom filter, thus enabling the system to drop irrelevant rows from lineitem.
But what if you are doing something more complex than a join of two tables (e.g., TPC-H Q5)? This is where predicate transfer comes to the rescue. It is a straightforward algorithm that propagates information between all tables involved in a join, thus increasing the number of rows that can be removed early.
The Algorithm
First, construct a join graph. Each vertex is a table (i.e., relation) and each edge is a join key (Fig. 1a):
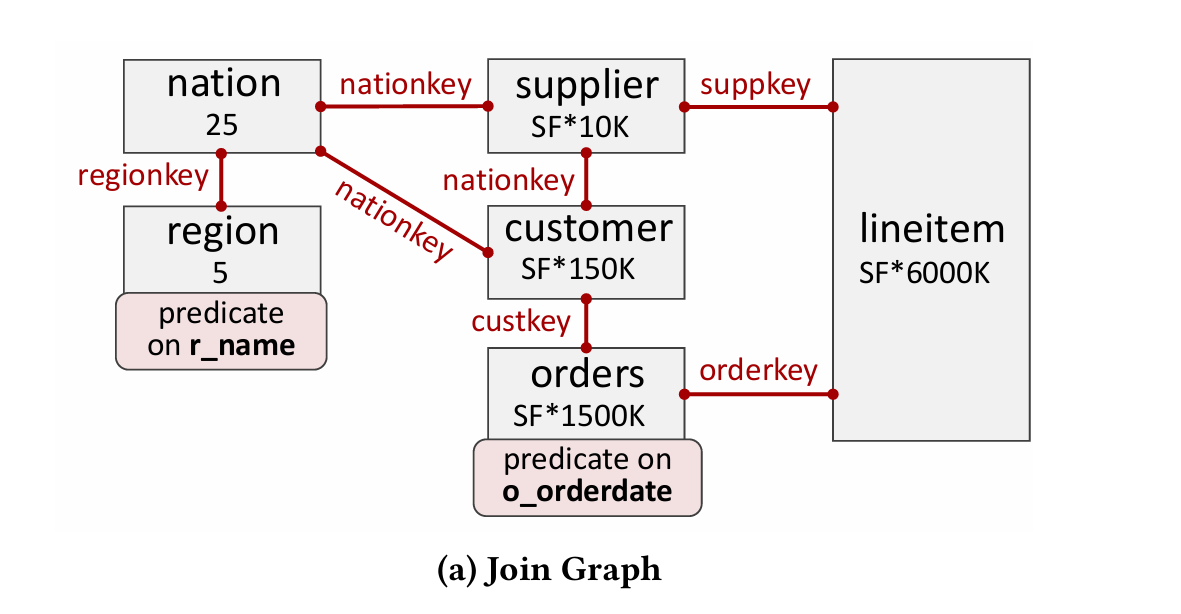
Next, propagate predicate information forwards. In the Q5 example:
Start by scanning the
regiontable to produce a bloom filter containingregionkeyvalues.Next, scan the
nationtable. While scanningnation, probe the input bloom filter based onregionkey. In that process, produce a new bloom filter based onnationkey.Next, scan the
suppliertable, using thenationkeybloom filter as input, and producing asuppkeybloom filter as output.Continue this process, creating new bloom filters (corresponding to the edges of the graph) at each step.
This process transfers filter information from tables with explicit predicates to all other tables. lineitem is the last table to be processed. Once forward propagation runs, the whole process runs in reverse (starting at lineitem).
Fig. 1b shows the join graph with a linear layout. The red arrows show the flow of information during the forward pass (flip the arrows in your mind for the backward pass).
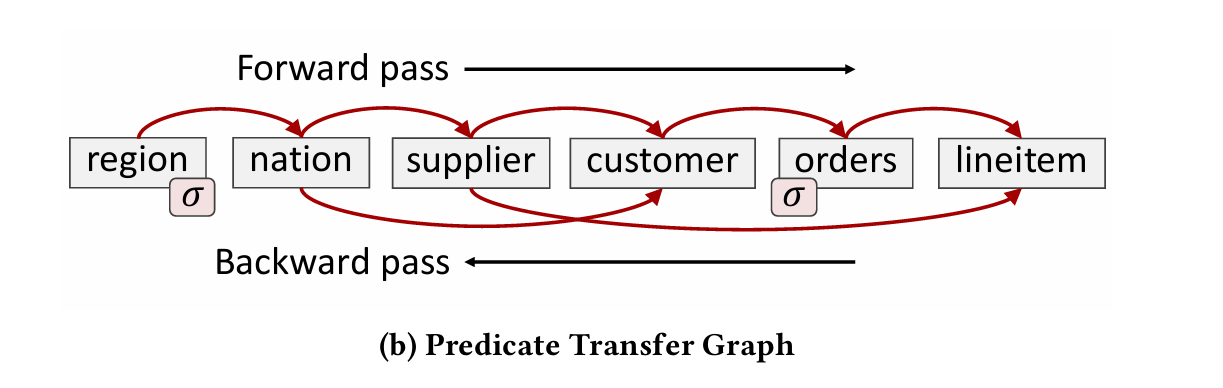
Once the forward and backward pass have completed, then all predicate information has been transferred to all relevant tables. This information can be used like a pushed-down filter when subsequently running the join.
This predicate transfer process is inspired by the Yannakakis algorithm, which is similar, but does not use bloom filters.
Results
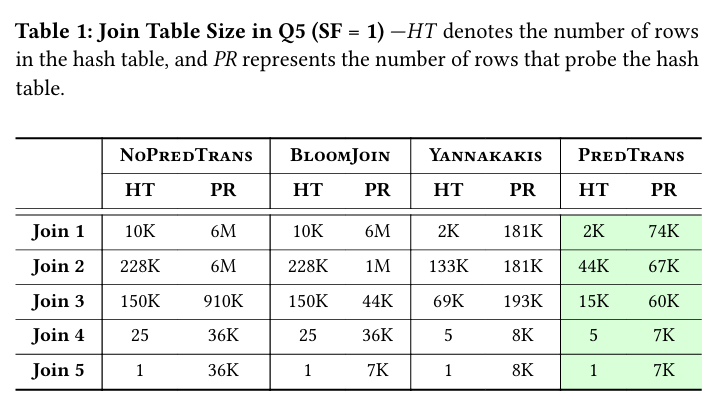
Table 1 shows the massive reduction in the number of rows processed by each join in Q5:
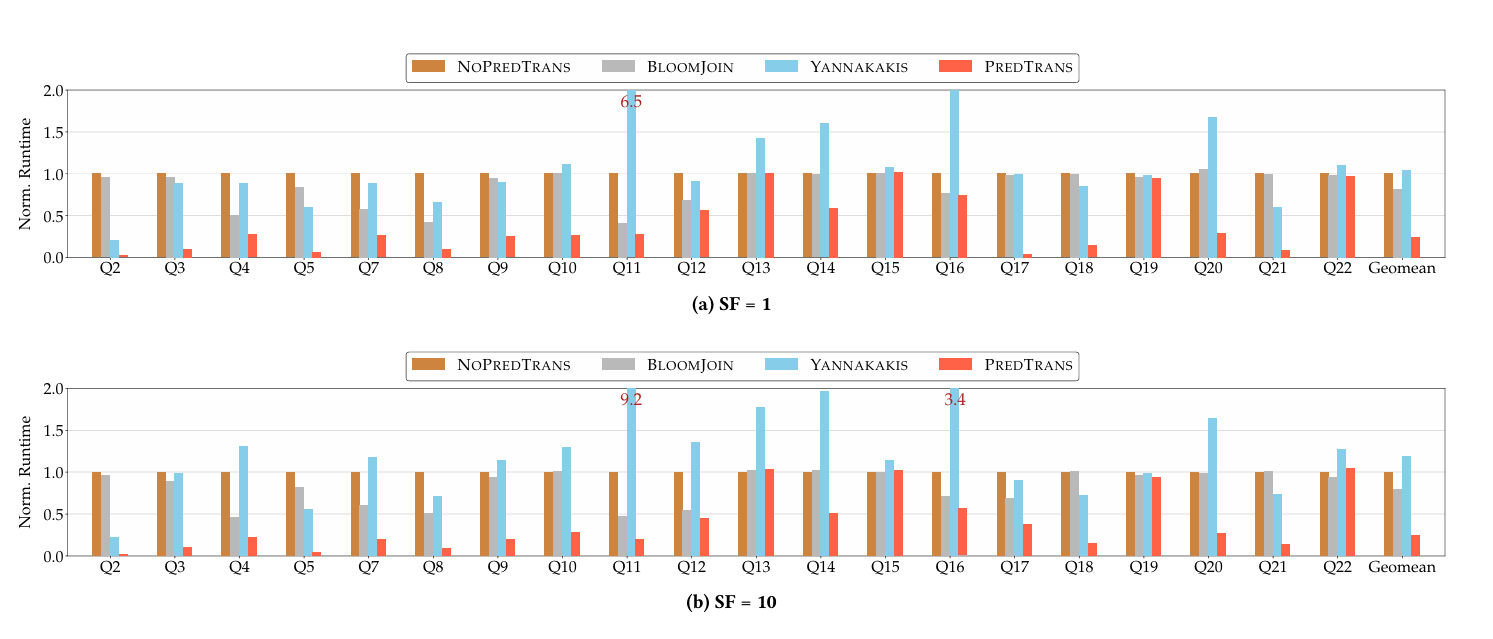
Here are end-to-end results for most TPC-H queries:
Dangling Pointers
An interesting omission here is that performance numbers are only reported for scale factors 1 and 10. I suspect that for large scale factors, the bloom filters stop fitting in CPU caches, and then the insert/probe cost becomes significant.
It would be interesting to see how to adapt this to a distributed setting, where tables are spread across multiple nodes and thus predicate information must be transferred across the network.
Great read!
Thanks for sharing the work of predicate transfer! The blog is very easy to read and inspiring!
For thoughts about distributed settings, there is a recent work in this year SIGMOD ("Accelerate Distributed Joins with Predicate Transfer") which mainly talks about how to extend predicate transfer to distributed settings.
For people who are interested, there is also another work in this year SIGMOD ("Debunking the Myth of Join Ordering: Toward Robust SQL Analytics") that demonstrates the robustness of predicate transfer to random join orders.