
Radshield: Software Radiation Protection for Commodity Hardware in Space
Putting the space back in user space

Radshield: Software Radiation Protection for Commodity Hardware in Space Haoda Wang, Steven Myint, Vandi Verma, Yonatan Winetraub, Junfeng Yang, and Asaf Cidon ASPLOS'25
If you read no further, here are two interesting factoids about outer space from this paper:
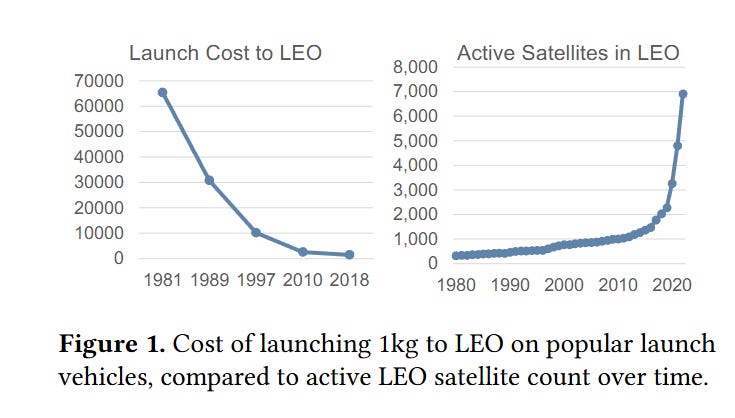
Launch costs have fallen 60x, with the current cost to launch 1kg to space clocking in at $1,400 (see Fig. 1 below).
Many satellites orbiting the Earth and devices sent to Mars use Snapdragon CPUs! I assumed that all chips leaving planet Earth would be specialized for space, apparently not.
This paper describes software solutions to deal with two common problems that occur in outer space: Single-Event Latchups and Single-Event Upsets, both of which are caused by radiation interfering with the normal operation of a circuit.
Single-Event Latchups
A single-event latchup (SEL) causes one portion of the chip to heat up. If left unmitigated, this can damage the chip. The solution to this is to detect the problem and reboot. The trick is in the detection.
The classic detection method monitors chip current draw. However, this technique fails with a modern off-the-shelf CPU which is designed to have a wide variability in current draw. When compute load increases, clock frequencies and voltages change, cores come out of sleep states, and power consumption naturally increases. The point of this design is to save power during idle periods, which is especially important for satellites which must get their power from the sun.
The solution proposed by this paper is called ILD. The idea is to predict the expected current draw based on a simple model that uses CPU performance counters (e.g., cache hit rate, instruction execution rate) as input. If the measured current draw is much larger than predicted, then the system is rebooted.
The model is not perfect, and the authors noticed that this scheme only works well when the CPU load is not too high. This “predict, check, reboot if necessary” cycle only occurs during relatively calm periods of time. The system is modified to force 3-second idle periods every 3 minutes to ensure that reliable measurements can be taken. An SEL takes about 5 minutes to damage the chip, the 3-minute period is chosen to be below that threshold.
Single-Event Upsets
A single-event upset causes the value of a bit to flip (in memory, cache, the register file, etc). There are two common solutions to SEUs:
Use ECC on stored data
Perform computations with triple modular redundancy (3-MR), which requires computing each result 3 times and choosing the most popular result if there is disagreement about the correct result
This paper deals with mitigating SEUs that affect user “space” code.
The authors define the term reliability frontier to represent the interface between hardware components that support ECC and those that do not. For example, if flash storage has ECC but DRAM does not, then flash is considered part of the reliability frontier.
A typical smartphone CPU advanced satellite chip has multiple CPU cores. One way to alleviate the compute cost of 3-MR is to compute all 3 results on 3 separate cores in parallel. A problem with this approach is that the CPU cores may share unreliable hardware. For example, the last level cache could be shared by all cores but not support ECC. If a bit flips in the LLC, then all cores will see the corrupted value, and parallel 3-MR will not detect a problem.
The paper proposes an algorithm called EMR. The idea is to break a computation into multiple tasks and associate metadata with each task that describes the subset of input data accessed by the task. Fig. 6 shows a motivating example. The task of analyzing an image may be decomposed into many tasks, where each task processes a subset of the input image.
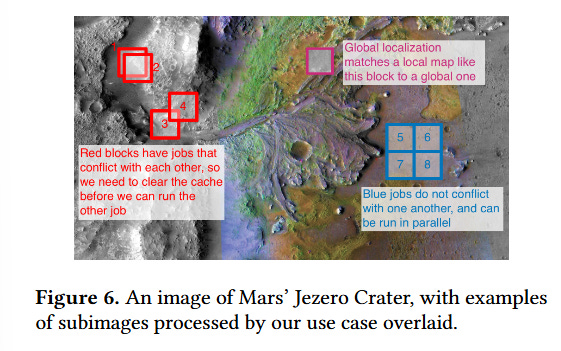
In EMR, there is an API to explicitly create tasks and specify the set of input data that each task reads from. EMR then runs tasks in multiple epochs. Within an epoch, no two tasks read the same input data. EMR invalidates caches up to the reliability frontier between epochs. If there are many tasks, and few epochs, then this system works great (i.e., it has high CPU utilization and does not spend too much time invalidating caches).
Results
Table 2 compares ILD performance in detecting SELs against a random forest model and a model that simply compares current draw against a fixed value:
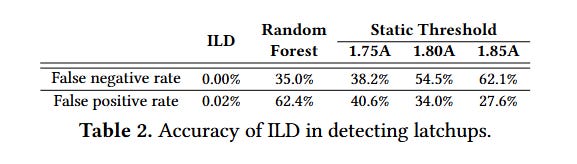
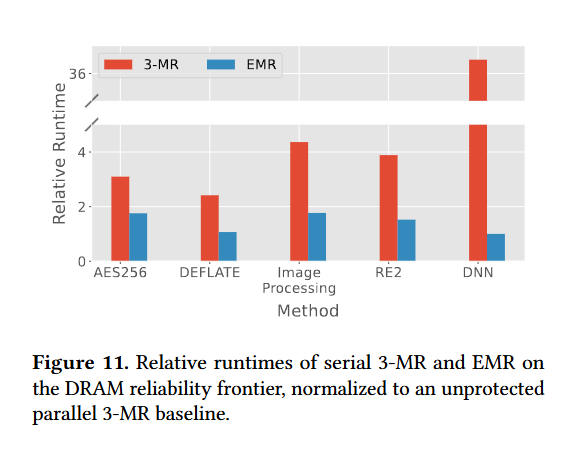
Fig. 11 shows the performance impact of EMR. Each result is normalized against a parallel version of 3-MR which ignores the problems associated with shared hardware. The red bars represent 3-MR run on a single core; the blue bars represent EMR.
Dangling Pointers
EMR would benefit from a system that detects when a programmer misspecifies the set of inputs that will be read. Maybe hardware or software support could be added to detect this kind of bug.
Couldn't a watchdog timer achieve this? You have some small radiation-hardened logic tied to an MMIO on the processor, and if the processor locks up the MMIO is not toggled and the timer expires, resetting the processor.