
Ripple: Asynchronous Programming for Spatial Dataflow Architectures

Ripple: Asynchronous Programming for Spatial Dataflow Architectures Souradip Ghosh, Yufei Shi, Brandon Lucia, and Nathan Beckmann PLDI'25
Spatial Dataflow Architectures
I can’t do better than this quote:
An SDA and its compiler represents a program as a dataflow graph (DFG). The DFG’s nodes are instructions, and its directed edges explicitly encode communication between instructions. There is no global instruction order (i.e., program counter) in the dataflow execution model. Instead, the dataflow firing rule governs execution: an instruction fires whenever its inputs are ready [28].
Or maybe one of these terms will ring a bell: TRIPS, WaveScalar, EDGE, CGRA, AI Engine.
The working assumption of the paper is that it is a fool’s errand to compile existing C code to an SDA. Rather, the fundamental aspects of the SDA model should be surfaced at the language level, so that the programmer can craft a solution that efficiently compiles to the SDA model. Ripple is an extension to C which exposes core SDA concepts to programmers.
Asynchronous Iterators
Think of an asynchronous iterator (async keyword) as a function implemented with imperative code. An async is not called like a regular function, rather “callers” explicitly push parameters to the implicit input queue associated with the async. “Callers” then precede on their merry way, not waiting for the body of the async to finish execution. Recursion is supported (i.e., the body of an async may enqueue parameters to itself, resulting in another execution of the same async).
asyncs can optionally be marked ind, which means that one “call to” an async does not need to finish before the next “call” starts. In other words, the ind keyword gives an async pipelined-parallel execution semantics. If the ind keyword is not specified, then the function is effectively single-threaded. The paper doesn’t use the term “thread”, but I think it fits well. I imagine the authors engaged in many debates about “thread” vs “task” terminology.
Atomic
The atomic construct is used to implement synchronization between threads tasks. The compiler knows the addresses of all values read and written by each atomic. Two executions of an atomic can run in a (pipelined) parallel manner if their read and write sets do not overlap.
Breadth First Search
Fig. 9 shows breadth first search implemented in Ripple. Note how Init and F both have the async keyword (callers do not wait for a “call” to complete). Line 8 contains an example “call” to F (which happens to be recursive). The push keyword makes it pretty clear at the call site that this is a “fire and forget” operation.
Lines 6-9 show the atomic construct. Note how nb is defined before the atomic construct. This means that if multiple tasks (executing F in a pipelined parallel manner) have different values of nb, then task N+1 can start executing the atomic before task N completes.

Full System Stack
The paper also describes an ISA, compiler, and hardware microarchitecture. Click the link at the top for all of the juicy bits.
Results
Riptide is prior work (also an SDA accelerator). A key difference between Ripple and Riptide is that Riptide assumes the input is unmodified imperative code, whereas Ripple introduces SDA-specific constructs to the source language.
Fig. 20 has performance numbers:
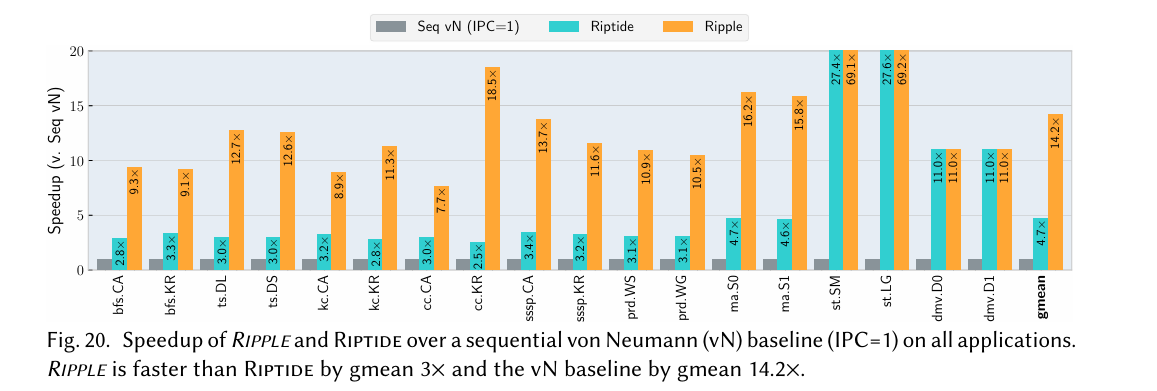
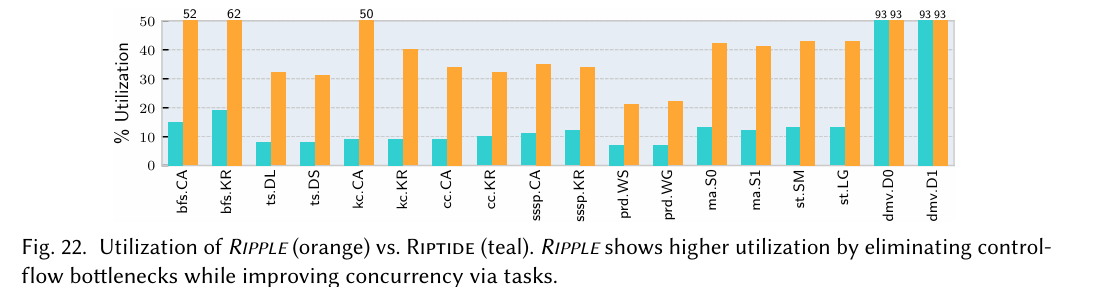
Fig. 22 goes into more detail about why Ripple outperforms Riptide (better utilization of the inherent parallelism of hardware):
Dangling Pointers
Supporting large applications (virtualizing a small SDA such that it can execute a data-flow graph that does not fit) seems like an open problem.
Ripple inherits C’s flat address space. It would be interesting to see what advantages a segmented address space would give.
I think a compiler could be used to translate Ripple to gates (ASIC or FPGA). I suspect the authors have been asked many times: “Is Ripple an HLS?” Kanagawa is prior work that I was involved with. The Kanagawa and Ripple languages have similarities, but the Kanagawa compiler generates gates (RTL).
Good point, Ripple atomics are similar to Bluespec rules. In addition to slow compile time, I think there is a risk of non-predictable performance if a programmer thinks two atomics or tasks can run in parallel but the compiler didn't get the memo.
Isn't this in a sense what BlueSpec is? I have heard (but in fairness have no personal experience with) that there is a fundamental performance issue with the BlueSpec compiler because the dependency tracking gets prohibitively expensive as the number of nodes in the DFG increases.