
RTSpMSpM: Harnessing Ray Tracing for Efficient Sparse Matrix Computations
When you have a hammer ...

RTSpMSpM: Harnessing Ray Tracing for Efficient Sparse Matrix Computations Hongrui Zhang, Yunan Zhang, and Hung-Wei Tseng ISCA'25
”Life Finds a Way”
I recall a couple of decades ago when Pat Hanrahan said something like “all hardware wants to be programmable”. You can find a similar sentiment here:
With most SGI machines, if you opened one up and looked at what was actually in there—processing vertexes in particular, but for some machines, processing the fragments—it was a programmable engine. It’s just that it was not programmable by you; it was programmable by me.
And now, twenty years later, GPU companies have bucked the programmability trend and added dedicated ray tracing hardware to their chips. Little did they know, users would find a way to utilize this hardware for applications that have nothing to do with graphics.
Sparse Matrix Multiply
The task at hand is multiplying two (very) sparse matrices (A and B). Each matrix can be partitioned into a 2D grid, where most cells in the grid contain all 0’s. Cells in A with non-zero entries must be multiplied by specific cells in B with non-zero entries (using a dense matrix multiplication for each product of two cells).
Ray Tracing?
The core idea is elegantly simple, and is illustrated in Fig. 5:
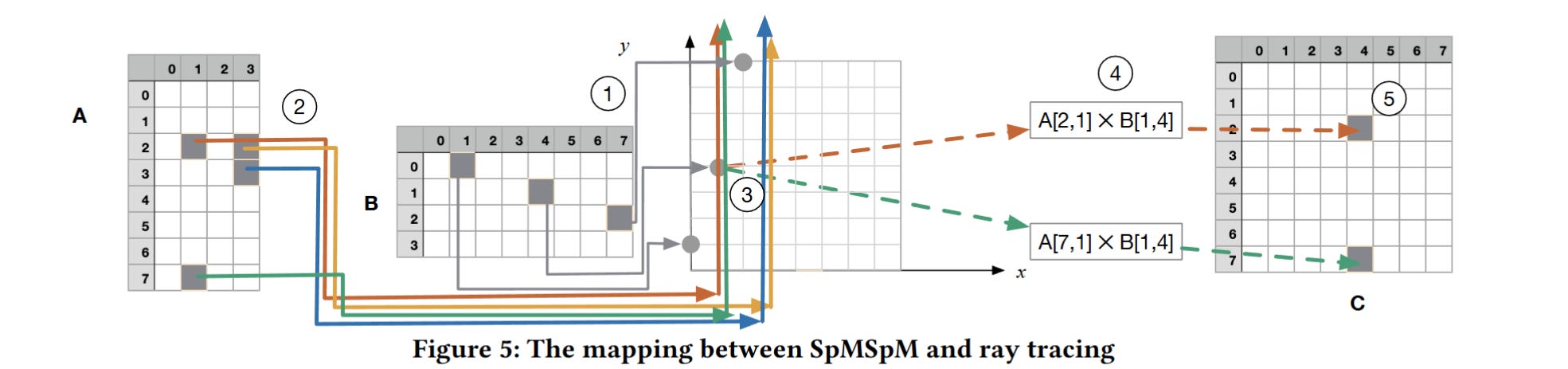
The steps are:
Build a ray tracing acceleration structure corresponding to the non-zero cells in
BFor each non-zero cell in
A:Trace a ray through
Bto determine if there are any non-zero cells inBthat need to be multiplied by the current cell inA
In fig. 5 the coordinates of the non-zero cells in matrix A are: [(2, 1) (2, 3) (3, 3) (7, 1)]. The figure shows rays overlaid on top of the result matrix, but I find it easier to think of the rays traced through matrix B.
The ray corresponding to the cell in A at (2, 1) has a column index of 1, so the algorithm traces a ray horizontally through B at row 1. The ray tracing hardware will find that this ray intersects with the cell from B at coordinate (1, 4). So, these cells are multiplied together to determine their contribution to the result.
Results
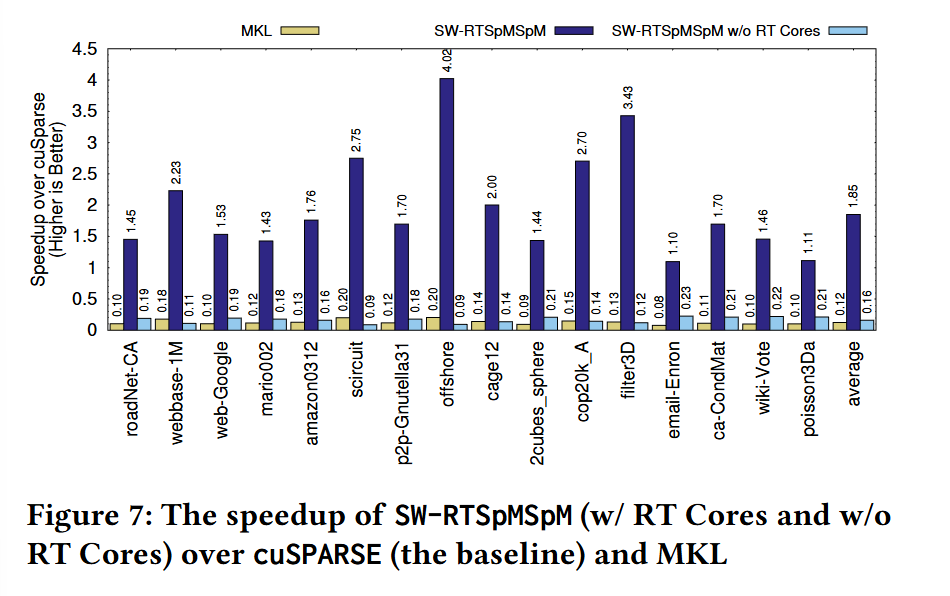
Fig. 7 has benchmark results. All results are normalized to the performance of the cuSPARSE library (i.e., values greater than one represent a speedup). MKL corresponds to the Intel MKL library running on a Core i7 14700K processor. The “w/o RT cores” bars show results from the same algorithm with ray tracing implemented in general CUDA code rather than using the ray tracing accelerators.
It is amazing that this beats cuSPARSE across the board.
Dangling Pointers
It seems like the core problem to be solved here is pointer-chasing. I wonder if a more general-purpose processor that is located closer to off-chip memory could provide similar benefits.