
Scalar Interpolation: A Better Balance between Vector and Scalar Execution for SuperScalar Architectures
Don't neglect your scalar ALUs

Scalar Interpolation: A Better Balance between Vector and Scalar Execution for SuperScalar Architectures Reza Ghanbari, Henry Kao, João P. L. De Carvalho, Ehsan Amiri, and J. Nelson Amaral CGO'25
This paper serves as a warning: don’t go overboard with vector instructions. There is a non-trivial amount of performance to be had by balancing compute between scalar and vector instructions. Even if you fear that automatic vectorization is fragile, this paper has some interesting lessons.
Vectorization Example
Listing 1 contains a vectorizable loop and listing 2 shows a vectorized implementation:


After achieving this result, one may be tempted to pat oneself on the back and call it a day. If you were a workaholic, you might profile the optimized code. If you did, you would see something like the data in table 1:
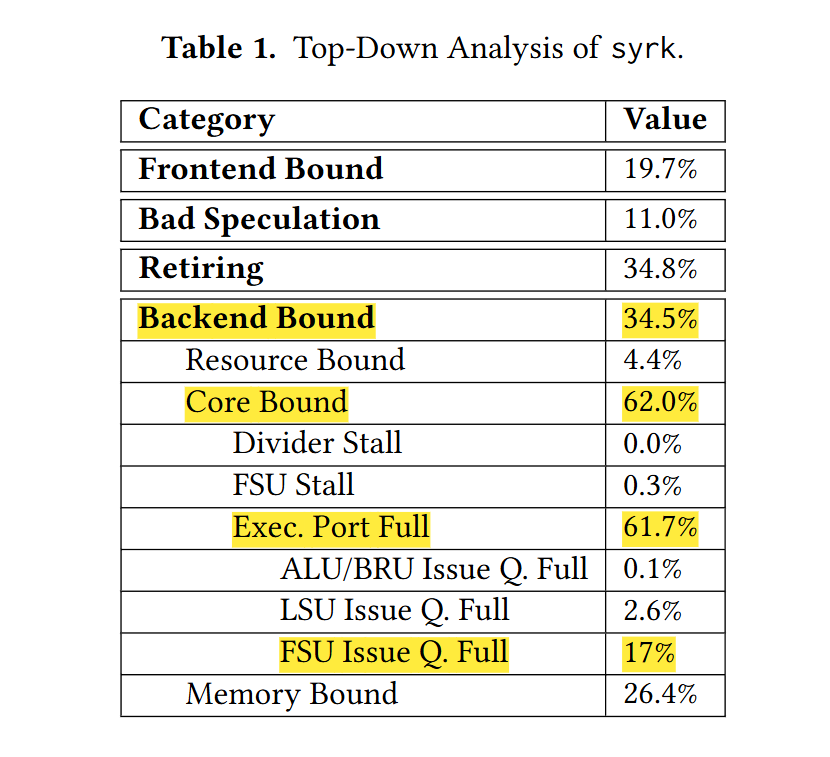
And you could conclude that this algorithm is compute-bound. But what do we really mean by “compute-bound”? A processor contains many execution ports, each with a unique set of capabilities.
In the running example, the execution ports capable of vector multiplication and addition are fully booked, but the other ports are sitting mostly idle!
Scalar Interpolation
Listing 3 shows a modified loop which tries to balance the load between the vector and scalar execution ports. Each loop iteration processes 9 elements (8 via vector instructions, and 1 via scalar instructions). This assumes that the processor supports fast unaligned vector loads and stores.

Section 3 has details on how to change LLVM to get it to do this transformation.
Results
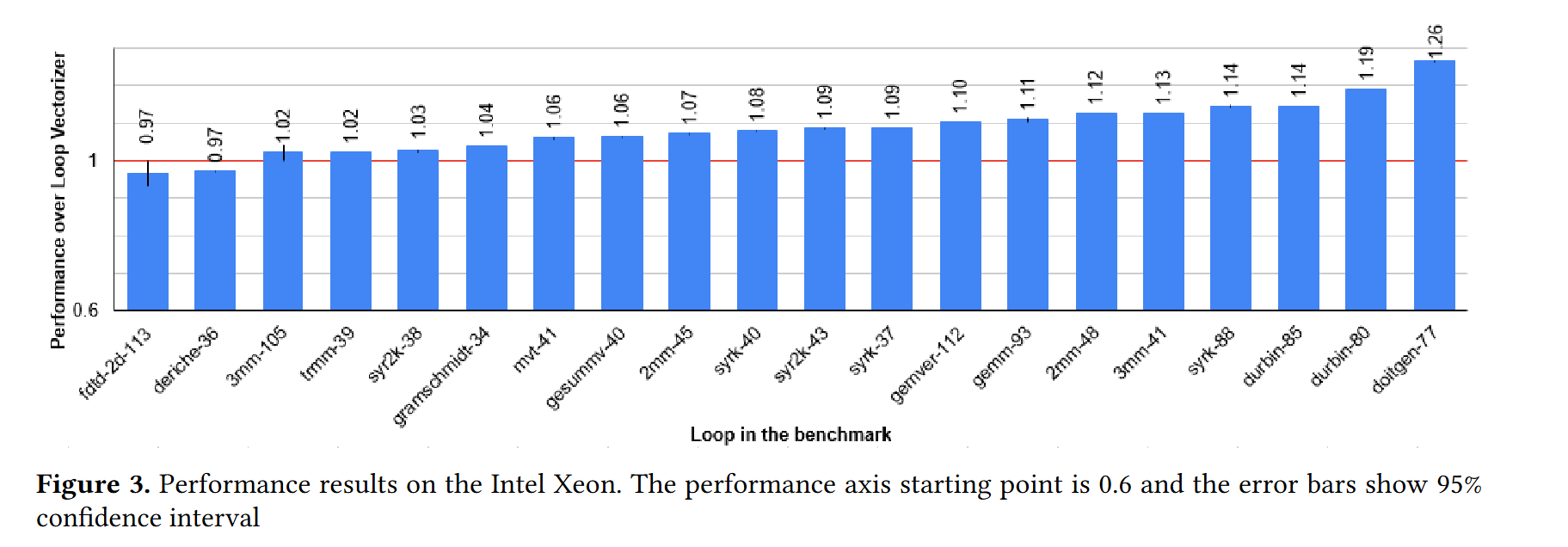
Fig. 3 shows benchmark results. By my calculations, the geometric mean of the speedups is 8%.
Dangling Pointers
This paper builds on top of automatic vectorization. In other words, the input source code is scalar and the compiler vectorizes loops while balancing the workload. An alternative would be to have the source code in a vectorized form and then let the compiler “devectorize” where it makes sense.