
State-Compute Replication: Parallelizing High-Speed Stateful Packet Processing
A trick to parallelize seemingly sequential code

State-Compute Replication: Parallelizing High-Speed Stateful Packet Processing Qiongwen Xu et al. NSDI'25
It is difficult for me to say if this idea is brilliant or crazy. I suspect it will force you to change some intuitions.
State, Skew, Parallelism
The goal is laudable: a framework to support generic packet processing on CPUs with the following properties:
Shared state between packets (this state can be read and written when processing each packet)
High performance with skewed distributions of flows (some flows may dominate the total amount of work, i.e., receive side scaling won’t work)
Throughput increases with the number of CPU cores used
As I see it, there are two options for parallel processing of network packets:
Distribute packets across cores
Pipeline parallelism
Both pose different problems for handling shared state. This paper advocates for distributing packets among cores and has a fascinating technique for solving the shared state problem.
Fast Forward State Replication
In this model, each core has a private replica of shared state. Incoming packets are sent to each core in a round-robin fashion. And now you are totally confused, how can this ever work? Enter the sequencer.
The sequencer is a hardware component (it could be a feature of the NIC or switch) which processes all incoming packets sequentially and appends a “packet history” to each packet immediately before it is sent to be processed by a core.
Say that four cores are used to implement a DDoS mitigator, and the crux of the DDoS mitigator state update depends on IP addresses from incoming packets. Each core receives a full copy of every fourth packet. Along with every fourth packet, each core also receives the IP addresses of the previous three packets (the packets that were sent to the other cores).
The per-core DDoS mitigator first updates its local state replica using the IP addresses of the previous three packets from the packet history. The paper calls this fast-forwarding the local state replica. At this point, the core has a fresh view of the state and can process the incoming packet.
Another way of thinking about this is that network functions can be decomposed into two steps:
Shared state update, which is relatively inexpensive, and only depends on a few packet fields
Packet processing, which is relatively expensive, and consumes both the shared state and a full packet as input
The shared state update computation is performed redundantly by all cores; there is no parallel speedup associated with it.
The authors argue that many network functions can be decomposed in such a manner and also argue that packet processing is fundamentally expensive because it involves the CPU overhead of programming a NIC to send an outgoing packet.
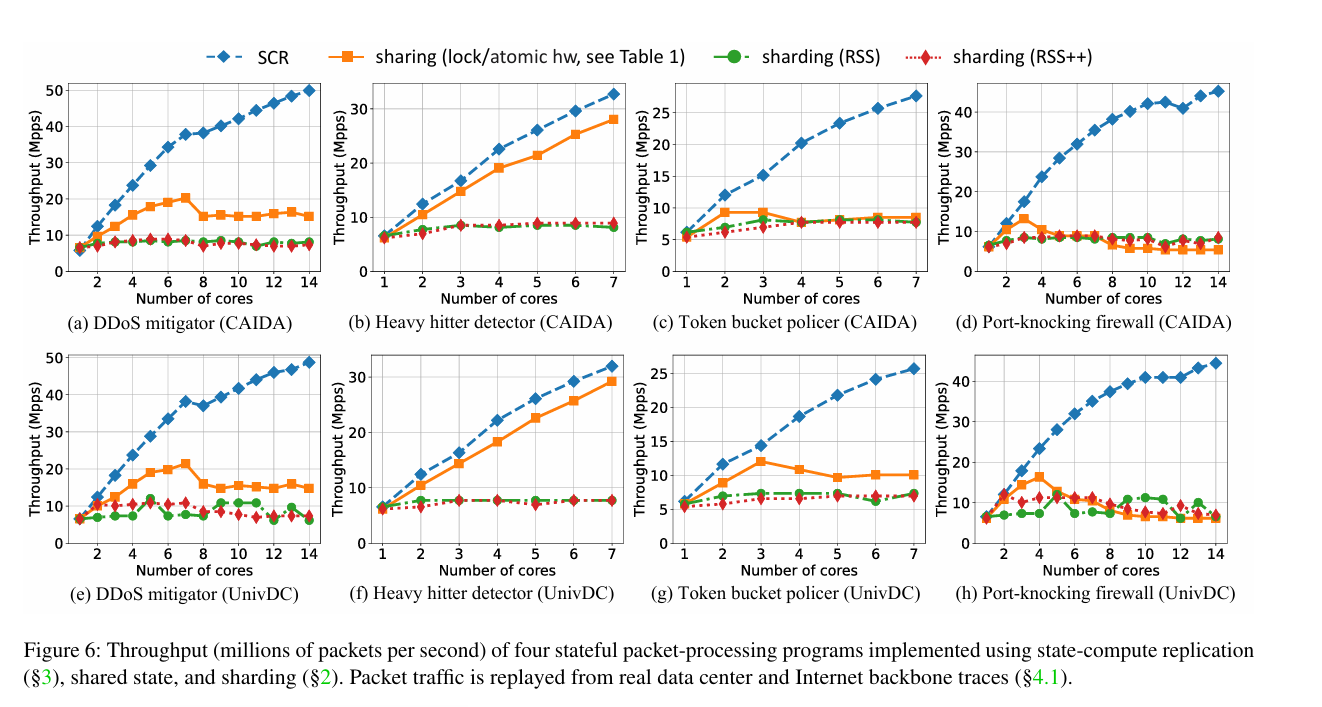
Results
Fig. 6 has results. The baseline (orange) implementation suffers in many cases because of cross-core synchronization. The sharding implementations suffer in cases of flow skew (a few flows dominating the total cost).
Dangling Pointers
There are heterodox and orthodox assumptions underpinning this paper.
An orthodox assumption is that the packet sequencer must run in hardware because it must process packets in order, and that is the sort of thing that dedicated hardware is much better at than a multi-core CPU.
A heterodox assumption is that many network functions can be expressed with the fast-forward idiom.
I wonder about the orthodox assumption. Hardware isn’t magic, is there a fundamental reason a multi-core CPU cannot handle 100Gbps networking processing with only pipeline parallelism?
Hi Blake, thanks for this post! I'm one of the authors of this paper and also the faculty member advising the lead grad student author.
I'll attempt to respond to your last question: why can pipelines process packets quickly while CPU cores can't, even if the latter is allowed to use pipelined parallelism? The answer lies in the partition of computation between the pipeline and the CPU, and not specifically whether something is done on line-rate hardware versus the CPU.
In pipelined parallelism, each stage of a pipeline finishes executing an operation over a piece of data within a single clock cycle, i.e., the time budget for each stage. Pipelines that are clocked faster have higher throughput, since they can admit a new piece of data to process in the pipeline in the next clock cycle.
However, stateful operations are challenging to clock fast because of dependencies. If the very next packet could require the most updated state from the previous packet, reading the state (from memory), computing the modification to the state, and writing it back (to memory) must together complete within a single clock cycle. You cannot break this operation into smaller computations spread over multiple pipeline stages. Fundamentally, when you want deterministic sequential semantics, fast pipelines (found in line-rate switch and NIC hardware, clocked at 1 GHz or higher, like RMT) must severely limit the kinds of permissible stateful operations.
In SCR, we do not perform complex stateful operations in the sequencer. Instead, we run the complex stateful computations (network functions) only on CPU cores. The main stateful operation we add to the line-rate pipeline is a ring buffer, something we show to be doable efficiently at high clock speeds.