
SuSe: Summary Selection for Regular Expression Subsequence Aggregation over Streams
Streaming aggregate statistics of regular expression matches

SuSe: Summary Selection for Regular Expression Subsequence Aggregation over Streams Steven Purtzel and Matthias Weidlich SIGMOD'25
Streaming Use Case
A common use case for regular expressions is to check whether a particular input string matches a regular expression. This paper introduces a new use case, which is generating statistics over streams. Imagine an infinite stream of characters constantly being processed, and a dashboard which a person occasionally views. The dashboard shows statistics, e.g., “there have been N matches in the last M hours”. It is OK for these statistics to be approximate.
The final quirk introduced by this paper is to allow for noise. In particular, all regular expressions implicitly accept “unexpected inputs” at any time and simply behave as if the unexpected input had never appeared. Counterbalancing this flexibility is a sliding time window which requires that if a particular subset of the input stream is going to match, it must do so with a bounded number of characters.
NFA Recap
A regular expression can be represented as an NFA. The N stands for non-deterministic, and that is the tricky bit. For example, say the regular expression to be matched against is AB*BC. This matches strings which begin with A, followed by 0 or more B characters, followed by exactly 1 B, followed by C. Another way to write this expression is: AB+C (B+ stands for “one or more Bs”).
Imagine you were designing a state machine to recognize strings which match this pattern. It starts off easy, the machine should expect the first input to be A. The next expected input is B, but then what? That first B could be one of many represented by the B*, or it could be the last B right before the C. The state machine doesn’t know how to classify the B inputs that it has seen until it sees the final C (or some other non-B character, indicating no match).
A common solution to this problem is like the metaverse, when that first B comes, split the universe into two, and then send all subsequent inputs to both. An easy way to implement this is to use a bit vector to track all possible states the NFA could be in. The NFA starts in the initial state (so only one bit is set), and transitions through states like you would expect (only one bit is set at a time). When that first B comes however, two bits are set, indicating that there are two possible ways the input could match.
Example
The NFA above can be represented with 6 states:
State 0 : Initial
State 1 : Matched A
State 2 : Matched AB*
State 3 : Matched AB*B
State 4 : Matched AB*BC
State 5 : Error (input does not match)The following table shows how the bit vector could evolve over time (one new input accepted each time step, bit vectors are written with the least-significant bit on the right):
State Counters
The key insight in this paper is to track states with counters, not bits. Each counter represents the number of matches that have been seen thus far in the stream. For example, when an A input comes along, the counter associated with state 1 is increased by one. When a C comes along, the counter associated with state 4 is increased by the value of the counter associated with state 3. Section 5.1 of the paper explains how counter increment rules can be derived for a specific NFA.
This system described by this paper contains multiple sets of counters. Some counters are global, and some are local to each input character. The purpose of the local counters is to allow for “garbage collection”.
The idea is that the system keeps a sliding window of the most important recent inputs, along with global and local state counters. When a new input comes, the local state counters are used to determine which input in the sliding window to delete. This determination is made based on an estimate of how likely each input is to generate a match.
When the user views the dashboard, then all matches within the sliding window are identified. It is OK if this process is expensive, because it is assumed to be rare.
Results
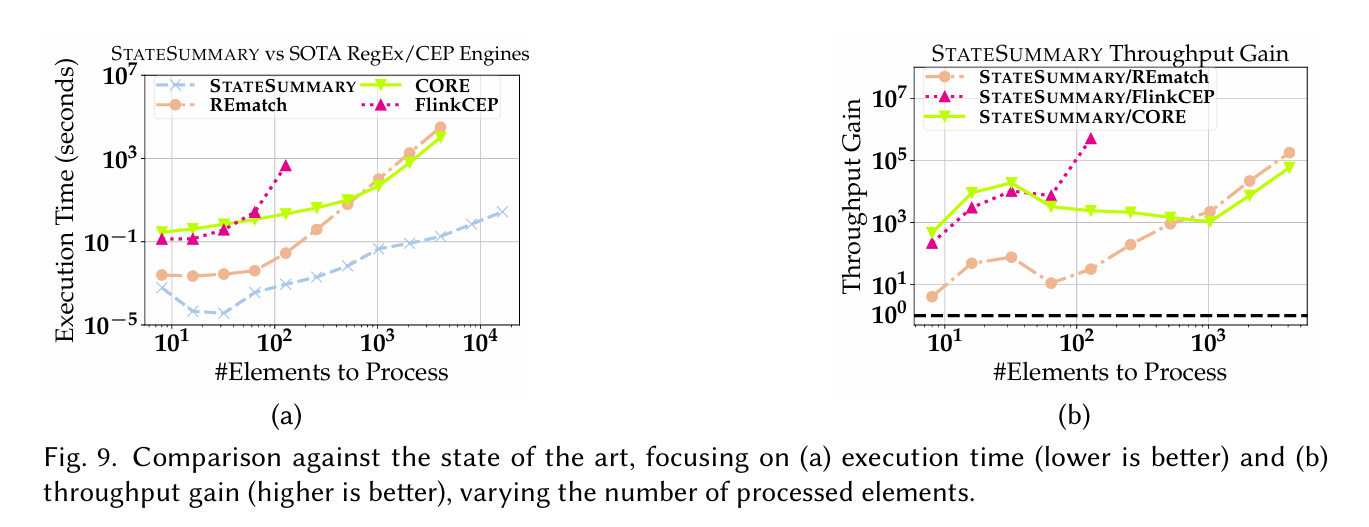
Fig. 9 has a comparison of this work (StateSummary) against other approaches:
Dangling Pointers
State machines are notoriously hard to optimize with SIMD or specialized hardware because of the fundamental feedback loop involved. It would be interesting to see if this approach is amenable to acceleration.