
The XOR Cache: A Catalyst for Compression
Two cache lines for the price of one

The XOR Cache: A Catalyst for Compression Zhewen Pan and Joshua San Miguel ISCA'25
Inclusive caches seem a bit wasteful. This paper describes a clever mechanism for reducing that waste: store two cache lines of data in each physical cache line!
The Idea
In most of the paper there are only two caches in play (L1 and LLC), but the idea generalizes. Fig. 1 illustrates the core concept. In this example, there are two cache lines (A, and B) in the LLC. A is also present in the L1 cache of a core.
Here is the punchline: the LLC stores A XOR B. If the core which has A cached experiences a miss when trying to access B, then the core resolves the miss by asking the LLC for A XOR B. Once that data arrives at the L1, B can be recovered by computing (A XOR B) XOR A. The L1 stores A and B separately, so as to not impact L1 hit latency.
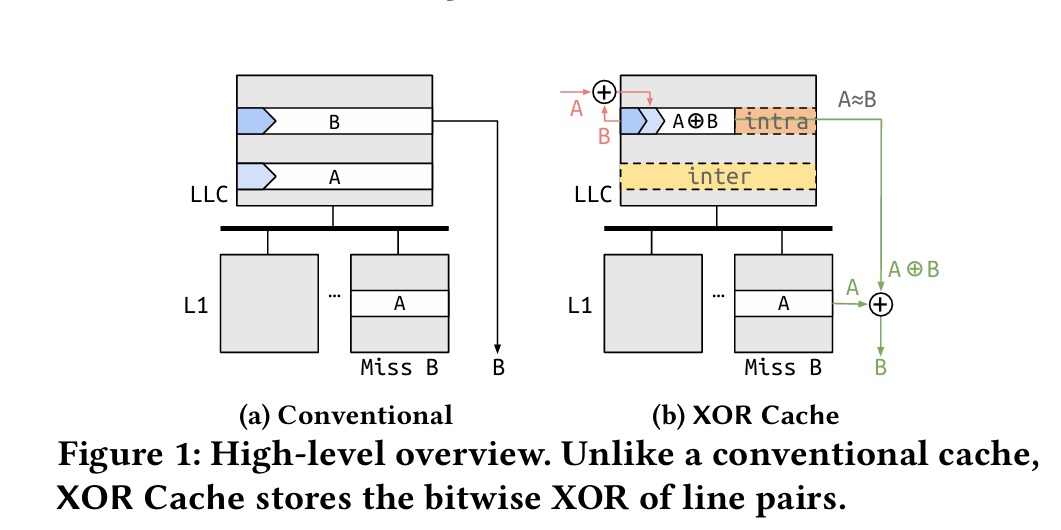
Coherence Protocol
The mechanics of doing this correctly are implemented in a cache coherence protocol described in section 4 of the paper. We’ve discussed the local recovery case, where the core which needs B already holds A in its L1 cache. If the core which requires B does not hold A, then two fallbacks are possible.
Before describing those cases, the following property is important to highlight. The cache coherence protocol ensures that if the LLC holds A XOR B, then some L1 cache in the system will hold a copy of either A or B. If some action was about to violate this property, then the LLC would request a copy of A or B from some L1, and use it to split A XOR B into separate cache lines in the LLC holding A and B.
Direct forwarding occurs when some other core holds a copy of B. In this case, the system requests the other core to send B to the core that needs it.
The final case is called remote recovery. If the LLC holds A XOR B and no L1 cache holds a copy of B, then some L1 cache in the system must hold a copy of A. The LLC sends A XOR B to that core which has A locally cached. That core computes (A XOR B) XOR A to recover a copy of B and sends it to the requestor.
Another tricky case to handle is when a core writes to B. The cache coherence protocol handles this case similar to eviction and ensures that the LLC will split cache lines as necessary so that all data is always recoverable.
Intra-Cache Line Compression
The LLC has a lot of freedom when it comes to deciding which cache lines to pair up. The policies described in this paper optimize for intra-cache line compression (compressing the data within a single cache line). The LLC hardware maintains a hash table. When searching for a partner for cache line C, the LLC computes a hash of the contents of C to find a set of potential partners.
One hash function described by the paper is sparse byte labeling, which produces 6 bits for each 8-byte word in a cache line. Each bit is set to 0 if the corresponding byte in the word is zero. The lower two bytes of each word are ignored. The idea here is that frequently the upper bytes of a word are zero. If two cache lines have the same byte label, then when you XOR them together the merged cache line will have many zero bytes (i.e., they have low entropy and are thus compressible).
The LLC can optimize for this case by storing compressed data in the cache and thus increasing its effective capacity. This paper relies on prior work related to compressed caches. The takeaway is that not only is there a potential 2x savings possible from logically storing two cache lines in one physical location, but there are also further savings in compressing these merged cache lines.
Results
Fig. 13 compares the compression ratio achieved by XOR cache against prior work (taller bars are better). The right-most set of bars show the geometric mean:
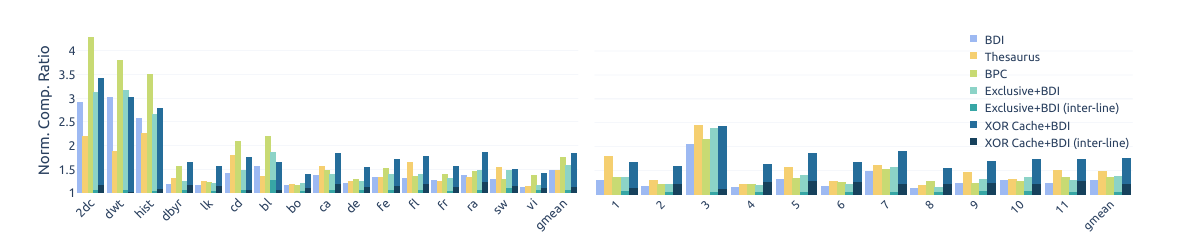
Fig. 15 shows performance impacts associated with this scheme:

Dangling Pointers
It seems to me that XOR Cache mostly benefits from cache lines that are rarely written. I wonder if there are ways to predict if a particular cache line is likely to be written in the near future.
I had the same experience!
Took me some time to get it, but such a simple but wonderful idea!