
Yield Not Thy Core
Dynamic distribution of data and code

Yield Not Thy Core Achilles Benetopoulos, Peter Alvaro, Andi Quinn, and Robert Soule EUROSYS’26
This paper describes a solution to the placement problem in distributed systems. If you model a computation as a directed graph, how do you optimally distribute the graph among a set of cooperating computers? The authors propose a dynamic placement system and implement it in Magpie.
Two Baselines
One common solution to the placement problem is to ship data over the network. For example, a set of compute nodes could access data via network requests to a separate set of nodes running Redis servers.
At the opposite end of the spectrum, code can be shipped over the network. The canonical example is expressing computation as a SQL query which is sent to the node(s) that hold the relevant data.
Magpie proposes a more fluid solution, where both code and data can move dynamically.
Objects
In Magpie, an object represents data that is operated on. What makes Magpie objects unique is that pointers to data stored in an object are encoded as (object ID, byte offset) tuples. This allows Magpie to dynamically move objects around the system without invalidating pointers. The downside of this approach is that it prevents traditional libraries (that rely on raw pointers) from being used in user code.
Magpie assumes a high degree of inter-object locality, so any given object is stored by exactly one node (i.e., a single object is never split between multiple nodes).
Code
User code is expressed in terms of nanotransactions and epics. A nanotransaction runs to completion on a single node and accesses a pre-specified set of objects. The Magpie runtime ensures that all objects accessed by a given nanotransaction are resident on a single node before executing the nanotransaction. The code for a nanotransaction is simple, because there is no need to query data over the network, and there is no need to deal with locking. If a hazard is present between two nanotransactions, they will execute serially. In Magpie, nanotransactions are written in Rust.
An epic is a computation graph where each vertex is a nanotransaction and each edge is a data dependency. In contrast to nanotransactions, a single epic can be distributed across multiple nodes. Magpie schedules nanotransactions once all data dependencies are satisfied. Conflicts between concurrently running epics are handled via snapshot isolation. Any particular epic has a consistent view of each object and may abort in the event of a conflict.
Scheduling and data movement are implemented hierarchically. A worker node can locally determine if it has ownership of all dependencies required for a nanotransaction. If this is the case, then the worker node executes the transaction immediately. Otherwise, the worker node uses a local ownership cache to try to determine if another node has all required dependencies and communicates with that node if possible. Failing that, scheduling is performed by a global orchestration node.
Results
Fig. 9 compares Magpie to memcached executing a workload that involves a user-specified read-modify-write operation:
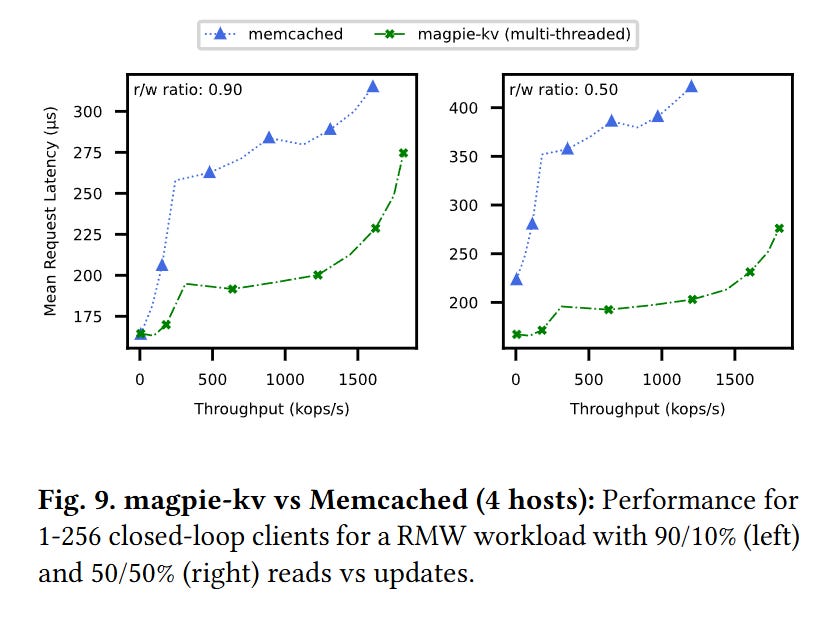
Magpie is able to offer a lower latency because it is able to ship the entire read-modify-write operation to the server that holds the relevant data, rather than requiring multiple roundtrips.
Dangling Pointers
Some applications may benefit from being able to indicate that an object is rarely changed and thus can be distributed among multiple nodes at the same time.