
Bounding Speculative Execution of Atomic Regions to a Single Retry
Hardware support for critical sections, transactional memory (and maybe OLTP)

Bounding Speculative Execution of Atomic Regions to a Single Retry Eduardo José Gómez-Hernández, Juan M. Cebrian, Stefanos Kaxiras, and Alberto Ros ASPLOS'24
Optimistic Atomic Regions
This paper proposes adding hardware support for a specific subset of atomic regions. An atomic region can either be a regular old critical section or a transaction in a system which supports transactional memory.
Speculative lock elision is a microarchitectural optimization to speculatively remove synchronization between cores. A mis-speculation results in a finite number of retries, followed by falling back to locking as specified by the program.
Hardware transactional memory (HTM) requires programmers to specify transactions at the language level. Again, conflicts are handled with a bounded number of retries, followed by executing user-specified “fallback” code.
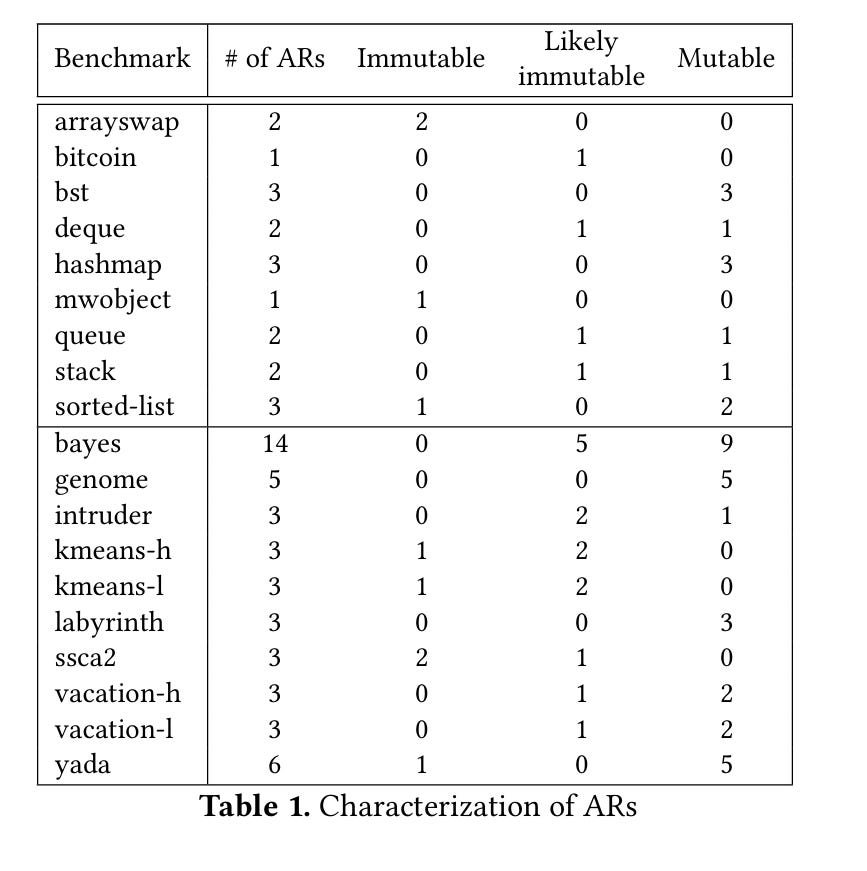
The key insight in this paper is that: many atomic regions can be implemented with at most a single retry. These atomic regions have an immutable set of memory addresses which they access. In other words, these regions will access the same set of cache lines on each retry.
Table 1 shows statistics for each atomic region in a set of benchmarks analyzed by the paper:
Cacheline-locked executed Atomic Region
The paper proposes hardware support for cacheline-locked executed atomic regions (CLEAR), to optimize execution of most atomic regions.
The first invocation on an atomic region is part of the discovery phase. The processor keeps track of properties (e.g., the set of cache lines accessed) of the atomic region. If no conflicts occur with other transactions, then this first invocation of the atomic region can commit.
If a conflict occurs, hardware finishes executing the atomic region, so that it gets a full picture of the set of cache lines touched by the region. The hardware then retries executing the atomic region, this time locking each cache line which will be accessed (locking in a sorted order to avoid deadlocks with other cores also locking cache lines). In most cases, this does the trick, and this second retry will succeed.
A few things can go wrong, but the paper claims they are not too common:
The atomic region can be too large for the core to keep track of all relevant metadata during discovery.
The atomic region could contain indirections, which means the set of cache lines accessed could change from run to run. The processor optimistically assumes the set of cache lines won’t change and detects if this assumption was incorrect.
For these reasons, the hardware must still have a fallback path (e.g., coarse-grained locking). But this is not the common case.
Results
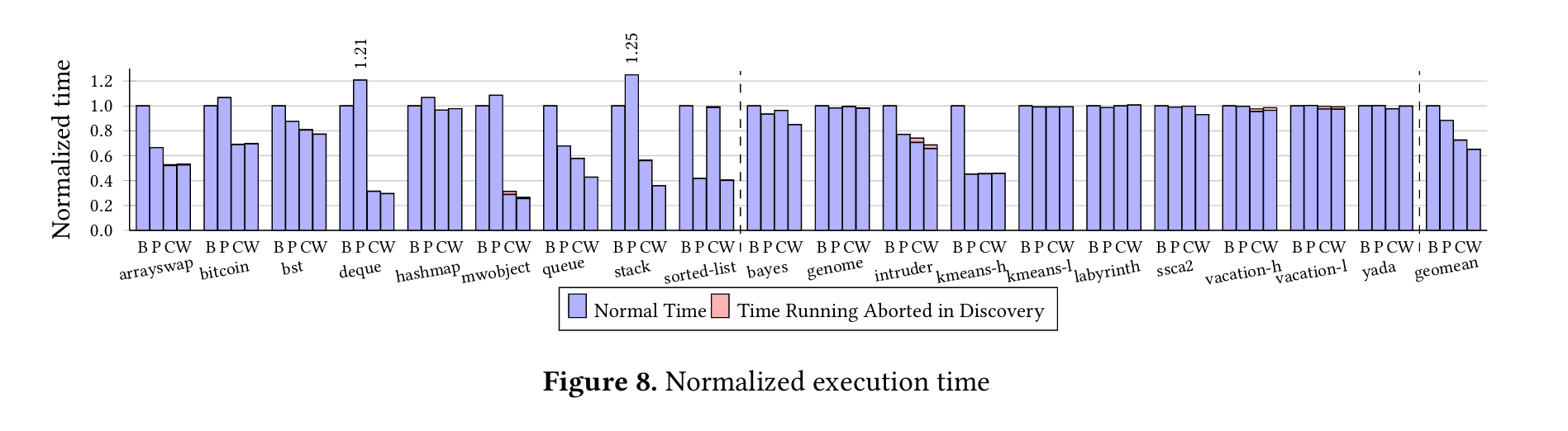
Fig. 8 has the headline results. B is a simplistic implementation of HTM (requester-wins). P is a more advanced implementation of HTM (PowerTM). C is CLEAR built on top of the requester-wins HTM design. PW is CLEAR built on top of the PowerTM implementation of HTM.
Dangling Pointers
Similar patterns appear in other domains. Ripple atomics require the read and write set of each atomic block to be known at compile time. Calvin runs OLTP transactions first as reconnaissance queries to determine the read/write sets of a transaction. From a language design point of view, it seems worth considering a special syntax for the subset of transactions which have immutable read/write sets.