
Fast and Scalable Data Transfer Across Data Systems
How hard can it be to move tuples from here to there?

Fast and Scalable Data Transfer Across Data Systems Haralampos Gavriilidis, Kaustubh Beedkar, Matthias Boehm, and Volker Mark SIGMOD'25
Relation Movement
We live in exciting times, unimaginably large language models getting better each day, and a constant stream of amazing demos. And yet, efficiently transferring a table between heterogeneous systems is an open research problem! An example from the paper involves transferring data from PostgreSQL to pandas. Optimizing this transfer time is important and non-trivial.
XDBC
The paper describes a system named XDBC. XDBC software runs on both the source and the destination data management systems (DMS), as illustrated by Fig. 4:
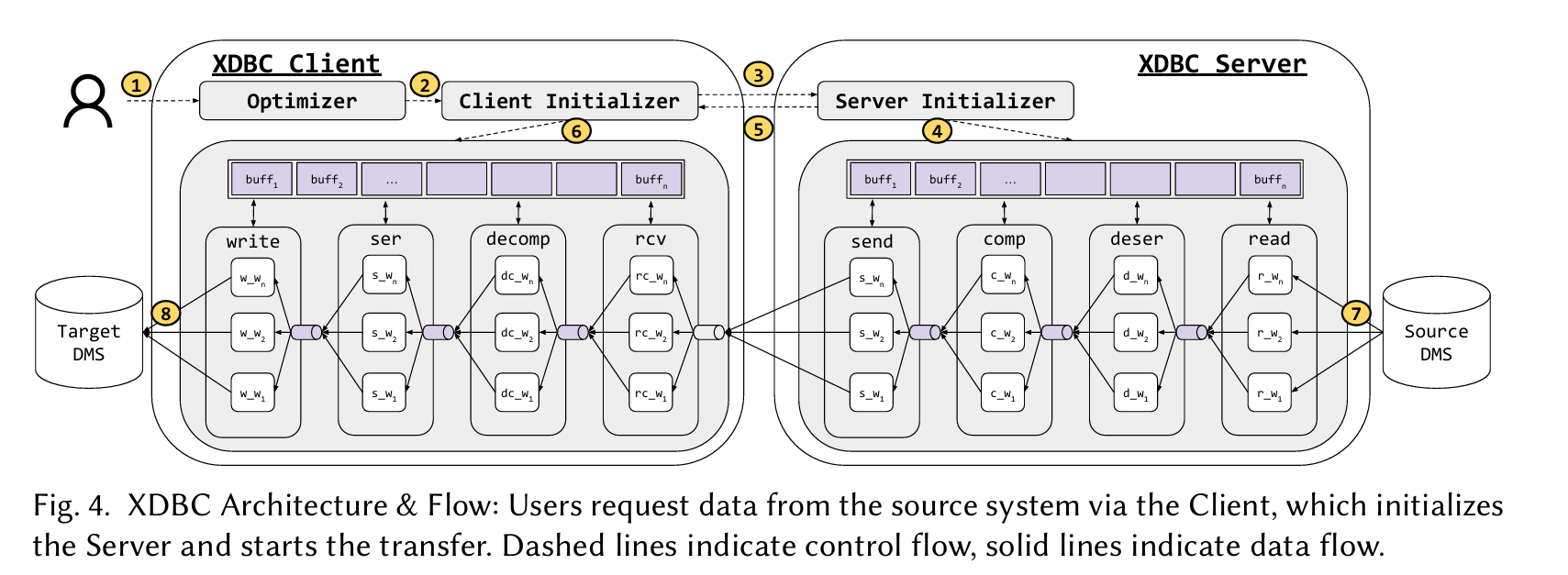
The XDBC client/server processes are organized as a pipeline. Data parallelism within a stage is exploited by assigning 1 or more workers (e.g., cores) to each stage. There are a lot of knobs which can affect end-to-end throughput:
Number of workers assigned to each task
Data interchange format (row-major, column-major, Arrow)
Section 4.1 of the paper claims the search space is so large that brute force search will not work, so a heuristic algorithm is used. The heuristic algorithm assumes accurate performance models which can estimate performance of each pipeline stage given a specific configuration. This model is based on real-world single-core performance measurements, and Gustafson’s law to estimate multi-core scaling.
The algorithm starts by assigning 1 worker to each pipeline stage (in both the client and server). An iterative process then locates the pipeline stage which is estimated to be the slowest and assigns additional workers to it until it is no longer the bottleneck. This process continues until no more improvement can be found, due to one of the following reasons:
All available CPU cores have been assigned
Network bandwidth is the bottleneck
If the process ends with more CPU cores available, then a hard-coded algorithm determines the best compression algorithm given the number of cores remaining. The data interchange format is determined based on which formats the source and destination DMSs support, and which compression algorithm was chosen.
XDBC vs Alkali
The XDBC optimizer has a lot of similarities with the Alkali optimizer. Here are some differences:
Alkali does not require tasks to be executed on separate cores. For example, Alkali would allow a single core to execute both the
deserandcomppipeline stages.Alkali uses an SMT solver to determine the number of cores to assign to each stage.
The Alkali performance model explicitly takes into account inter-core bandwidth requirements.
Alkali doesn’t deal with compression.
Results
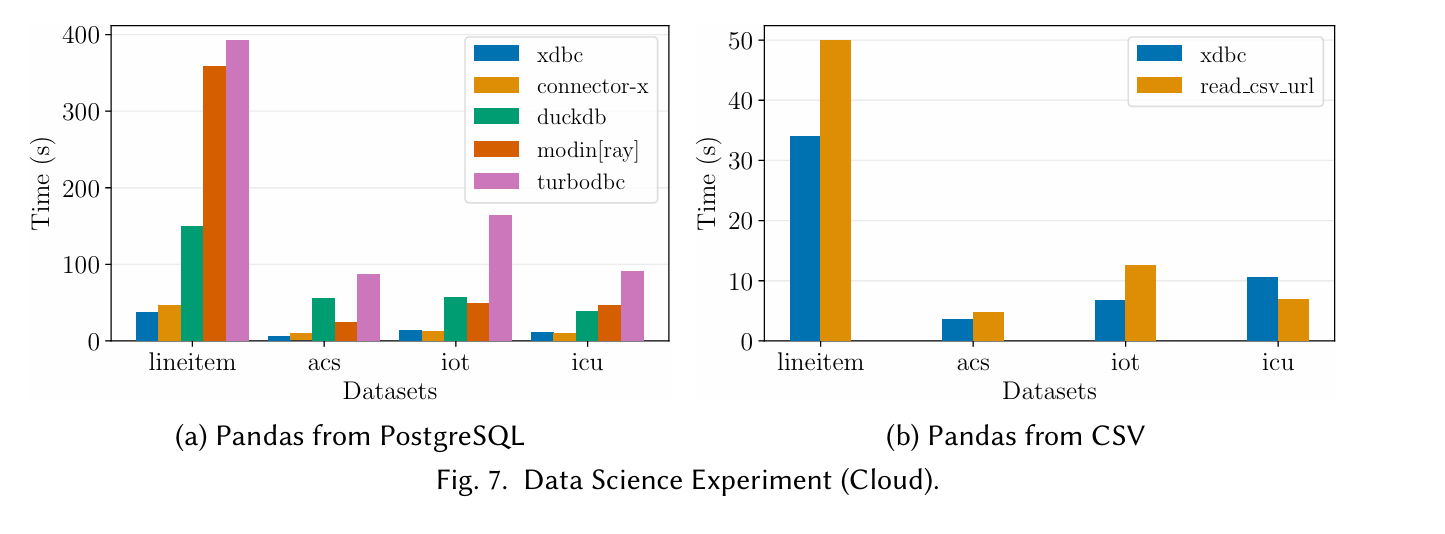
Fig. 7(a) shows results from the motivating example (PostgreSQL→Pandas). Fig. 7(b) compares XDBC vs built-in Pandas functions to read CSV data over HTTP. connector-x is a more specialized library which supports reading data into Python programs specifically.
Dangling Pointers
There are many search spaces which are too large for brute force. Special-case heuristic algorithms are one fallback, but as the Alkali paper shows, there are other approaches (e.g., LP solvers, ILP solvers, SMT solvers, machine learning models). It would be great to see cross-cutting studies comparing heuristics to other approaches.
Yeah, that makes a lot of sense. It's a bit recursive to think of an AI model which optimizes data transfer to enable faster training of another AI model.
Are you familiar with AlphaTensor? When you said "There are many search spaces which are too large for brute force. Special-case heuristic algorithms are one fallback" it made me think of this research. They use AI models to narrow the search space and then more traditional algorithms take over.
https://deepmind.google/discover/blog/discovering-novel-algorithms-with-alphatensor/