
Hapax Locks: Scalable Value-Based Mutual Exclusion
Spin locks with less coherence traffic

Hapax Locks: Scalable Value-Based Mutual Exclusion Dave Dice and Alex Kogan PPoPP'26
This paper describes a locking algorithm intended for cases where spinning is acceptable (e.g., one thread per core systems). It is similar to a ticket lock but generates less coherence traffic. Each lock/unlock operation causes a constant number of cache lines to move between cores, regardless of the number of cores involved or how long they spin for.
As we’ve seen in a previous paper, polling a value in memory is cheap if the cache line is already local to the core which is polling.
Basic Algorithm
A Hapax lock comprises two 64-bit fields:
ArriveDepart
Additionally, there is a global (shared among all Hapax locks) 64-bit sequence number. Each time a thread attempts to lock a Hapax lock, it generates a Hapax value which uniquely identifies the locking episode. A locking episode is a single lock/unlock sequence performed by a specific thread. A Hapax value is generated by atomically incrementing the sequence number. It is assumed that the 64-bit counter additions will never overflow.
Next, the locking thread atomically exchange the value of Arrive with the Hapax value it just generated. This exchange operation generates a total ordering among Hapax values. It is a way for threads to cooperatively decide the order in which they will acquire the lock.
Say thread A generates Hapax value N and stores it into Arrive (via an atomic exchange operation). Next, thread B generates Hapax value M and atomically exchanges the value of Arrive with M. The result of the exchange operation performed by B will be N. At this point, thread B knows that it is directly behind thread A in the queue and must wait for thread A to release the lock.
To finish acquiring the lock, threads continually poll Depart, waiting for Depart to equal the Hapax value of the preceding locking episode. In the example above, thread B polls Depart until it sees the value N. At this point, the lock has been acquired. Unlocking is implemented by storing the Hapax value used by the unlocking thread into Depart. In the running example, thread B would unlock the lock by storing the value M into Depart.
This algorithm generates a lot of coherence traffic. In particular, the cache line which holds the sequence number would move between cores each time a new Hapax value is generated. Also, each store to Depart would send coherence traffic to each core which had recently polled the value of Depart. The paper has two techniques to address these issues.
Hapax Value Amortization
While the sequence number monotonically increases, the values stored in Arrive and Depart do not. There are two reasons for this. First, a single sequence number is shared among all Hapax locks. The second reason is that multiple threads can generate Hapax values and then race to perform the atomic exchange operation. For example, thread A could generate a Hapax value of N while thread B generates a Hapax value of N+1. They then race each other to atomically exchange their Hapax value with the value of Arrive. If thread B wins the race, then Arrive will first take on the value N+1, and then later it will have the value N.
Once you realize that the values of Arrive and Depart are not monotonically increasing, it is straightforward to see how the generation of Hapax values can be made cheap. A thread can hoard a batch of Hapax values with a single atomic add operation. For example, a thread could atomically increase the value of the sequence number by 1024. At this point, the thread has allocated 1024 Hapax values for itself that it can use in the future without accessing the cache line which holds the shared sequence number. The paper proposes allocating Hapax values in blocks of 64K.
Depart Amortization
The paper proposes adding an additional array which serves a similar role as Depart. The number of elements in the array should be greater than the number of cores (the paper uses an array of 4096 values). Like the sequence number, this array is shared among all Hapax locks.
When a thread writes its Hapax value into Depart, the thread also stores its Hapax value into one of the 4096 elements. The array index is determined by the Hapax value. Many potential hash functions could be used. The paper proposes hashing bits [27:16] of the Hapax value. The 16 is related to the allocator block size.
In the locking sequence, a thread loads the value of Depart once. If the value of Depart does not match the expected Hapax value, then the locking thread polls the appropriate element of the shared array. The thread polls this element until its value changes. If the new value is the expected value of Depart, then the lock has been acquired. If not, then a hash collision has occurred (e.g., a locking episode associated with a different Hapax lock caused the value to be updated). In this case, the thread starts over by checking Depart and then polling the array element if necessary.
This scheme minimizes coherence traffic associated with polling. When an unlocking core stores a value into an array element, the associated cache line will typically be present only in the cache of the next core in line. Coherence traffic is only generated related to the locking and unlocking cores. Other threads (which are further back in the line) will be polling other array elements and thus be loading from other cache lines and so the cores those threads are running on won’t see the coherence messages.
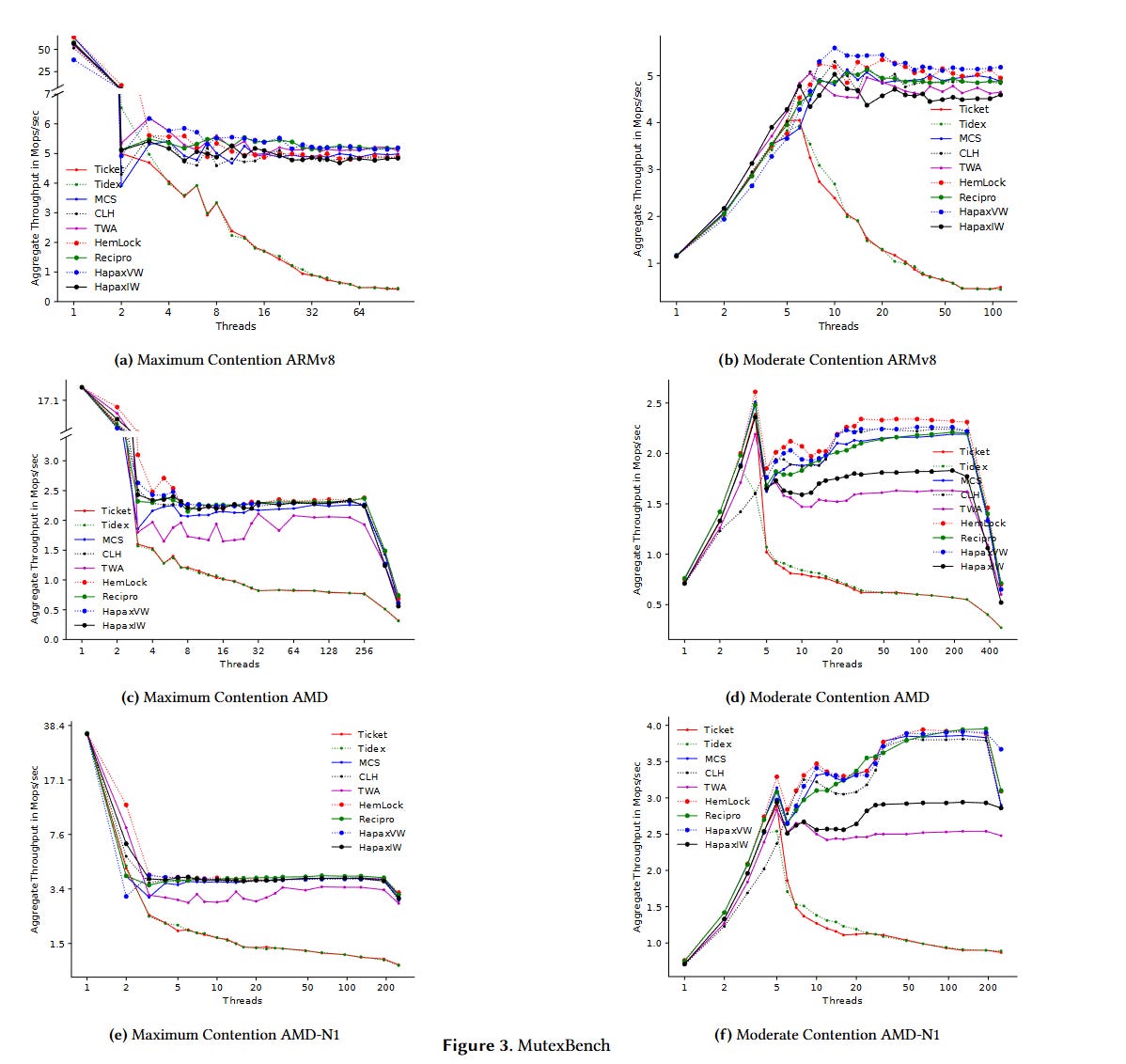
Results
Fig. 3 has results from a microbenchmark. Hapax locks scale much better than ticket locks and go head-to-head with other state-of-the-art locking algorithms. The Hapax implementation is so concise (about 100 lines) that the authors included C++ source code in the paper.
Dangling Pointers
The big downside of spinning is that it wastes cycles in the case where there are other threads that the OS could schedule. I wonder if there is a lightweight coordination mechanism available. For example, the OS could write scheduling information into memory that is mapped read-only into user space. This could be used to communicate to the spinning code whether or not there are other threads ready to run.