
Re-architecting End-host Networking with CXL: Coherence, Memory, and Offloading
CXL Deep Dive

Re-architecting End-host Networking with CXL: Coherence, Memory, and Offloading Houxiang Ji, Yifan Yuan, Yang Zhou, Ipoom Jeong, Ren Wang, Saksham Agarwal, and Nam Sung Kim MICRO'25
This paper is the third one that I’ve posted about which deals with the subtleties of interfacing a NIC and a host CPU. Here are links to the previous posts on this subject:
Disentangling the Dual Role of NIC Receive Rings
CEIO vs rxBisect: Fixing DDIO’s Leaky DMA Problem
The authors bring a new hammer to the construction site: CXL, which offers some interesting efficiencies and simplifications.
Two PCIe Problems
This paper shows how CXL can address two specific problems with the HW/SW interface of a typical PCIe NIC:
After the host prepares a packet to be transmitted, it notifies the NIC with a MMIO write. This MMIO write is expensive because it introduces serialization into the host processor pipeline.
When the NIC sends a received packet to the host, ideally it would write data to the LLC rather than host DRAM. However, if the host CPU cannot keep up, then the NIC should have a graceful fallback.
CXL Type-1
CXL Type-1 devices are asymmetric: the device has coherent access to host memory, but the host does not have coherent access to device memory. Practically speaking, both packet descriptors and packet payloads must still be stored in host memory (no change from PCIe based NICs).
Because the NIC has coherent access to host memory, it can safely prefetch receive descriptors (RxDs) into an on-NIC cache. When a packet arrives, the NIC can grab a descriptor from the cache and thus avoid an expensive host memory read to determine where to write packet data. If the host CPU updates a RxD after the NIC has prefetched it, the CXL cache coherence protocol will notify the NIC that it must invalidate its cached data.
Coherence also enables the tail pointers for transmit ring buffers to be safely stored in host memory. The host networking stack can update a tail pointer with a regular store instruction (rather than an MMIO write). The NIC can continually poll this value, using coherent reads. If the tail index pointer has not been updated since the last poll, the NIC will read a cached value and not generate any PCIe traffic.
CXL Type-2
CXL Type-2 NICs allow packets and descriptors to be stored in NIC memory. The host CPU can cache data read from the NIC, as the NIC will generate the necessary coherence traffic when it reads or writes this data. The design space (what data goes into what memory) is large, and the results section has numbers for many possible configurations.
Section 5.3 of the paper describes how a type-2 NIC can intelligently use the NC-P CXL operation to write received packet data directly into the host LLC. This is similar to DDIO (described in the two papers linked at the top of this post), but the key difference is that the NIC is in the driver’s seat.
The CEIO paper proposes monitoring LLC usage and falling back to storing received packets in DRAM local to the NIC if the LLC is too full. With CXL, the NIC has the option to write data to host memory directly (bypassing the LLC), thus avoiding the need for DRAM attached to the NIC.
Results
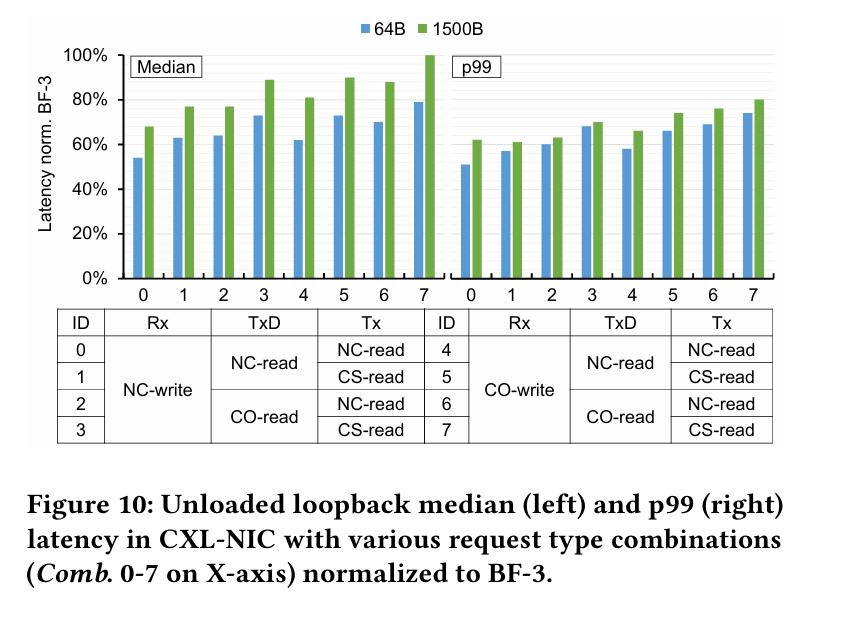
The authors implemented a CXL NIC on an Altera FPGA. They compared results against an nVidia BlueField-3 PCIe NIC. Fig. 10 compares loopback latency for the two devices, normalized to the BlueField-3 latency (lower is better) for a variety of CXL configurations.
Dangling Pointers
One fact I took away from this paper is that CXL coherence messages are much cheaper than MMIOs and interrupts. Burning a CPU core polling a memory location seems wasteful to me. It would be nice if that CPU core could at least go into a low power state until a relevant coherence message arrives.
sad they didn't release the artifact, could have been a good tool for the community