
LightDSA: Enabling Efficient DSA Through Hardware-Aware Transparent Optimization

LightDSA: Enabling Efficient DSA Through Hardware-Aware Transparent Optimization Yuansen Wang, Teng Ma, Yuanhui Luo, Dongbiao He, Zheng Liu, and Yunpeng Chai EUROSYS'26
This paper describes performance characteristics of the Intel DSA hardware accelerator, and software techniques to maximize performance when using DSA.
My takeaway is: the DSA supports a variety of convenience features, but each one is so expensive that you are better off adding software complexity to avoid these paths.
DSA Overview
The Data Streaming Accelerator (DSA) is a hardware accelerator in recent Intel chips. It can implement simple memory operations like memcpy, memset, memcmp, and CRC generation. Fig. 2 contains a high-level diagram of the DSA architecture.
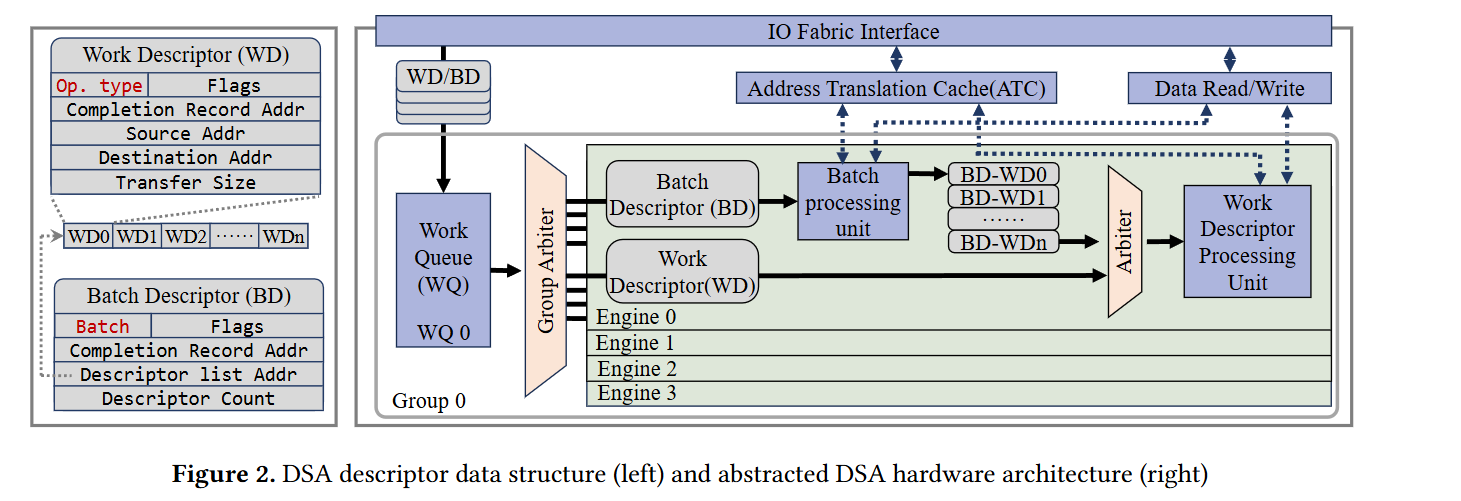
Operations are written into work queues as 64-byte descriptors. A work descriptor (WD) describes a single operation, whereas a batch descriptor (BD) references many work descriptors. A batch is the fundamental unit of control (the DSA signals the CPU when a batch has completed). The DSA contains multiple engines and arbiters to spread work across the engines. Source and destination buffers accessed by the DSA do not need to be pinned into memory, the DSA can handle page faults.
Page Faults
The DSA supports demand faulting via the page request service (PRS). This enables the DSA to send an interrupt to the OS (via the IOMMU) requesting the OS to resolve the fault.
This paper reports a similar finding to a previous paper looking at the PCIe page request interface: demand faulting is convenient, but slow. The LightDSA authors recommend that software forcibly fault in pages before submitting descriptors.
Alignment
The DSA supports operations that require unaligned reads and writes of data from/to DRAM but the authors find that 64-byte aligned accesses are much faster. Fig. 8 has some numbers, even 32-byte alignment is expensive (compare the light green and dark green bars).
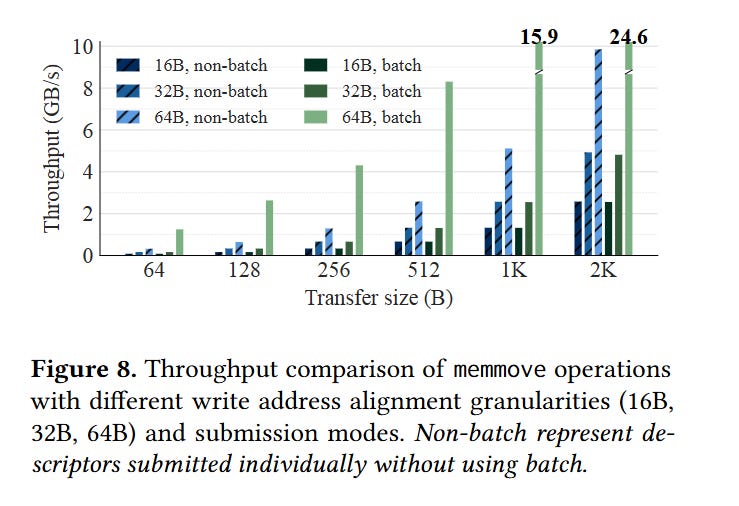
The authors recommend having software ensure that all writes performed by the DSA are 64-byte aligned. Software can do this by executing the operation for the first few bytes of each task, up until the destination buffer is 64-byte aligned.
Write Ordering
Like many HW/SW interfaces, the DSA writes both result data and metadata to memory. Result data is associated with each work descriptor, while completion metadata is associated with each batch descriptor. Metadata is read by software to learn when an operation completes. In such a scheme, it is important that software observes the batch metadata write after the result writes have completed. If the metadata write can land first, then software may try to read the result buffer before it has actually been updated.
The DSA supports multiple traffic classes (TC). As with discrete PCIe accelerators, writes from the DSA associated with the same traffic class will land in host memory in order (these are posted writes). However, writes associated with different TCs may be reordered. Here is a previous paper that describes performance problems with reordering.
Section 3.8 of the DSA architecture specification describes two choices that software developers have. Either they should configure work descriptors and batch descriptors to use the same traffic class, or they should configure the DSA to enforce ordering via the DRDBK (readback) flag. When that flag is set, the DSA will ensure that all result writes have landed in host memory by issuing a read request to read the most recently written result data back to the DSA, waiting for the response to come back, and then issuing metadata writes associated with the batch descriptor. Discrete PCIe devices can use the same trick to enforce ordering across traffic classes.
Fig. 7 shows the performance cost of using this feature:
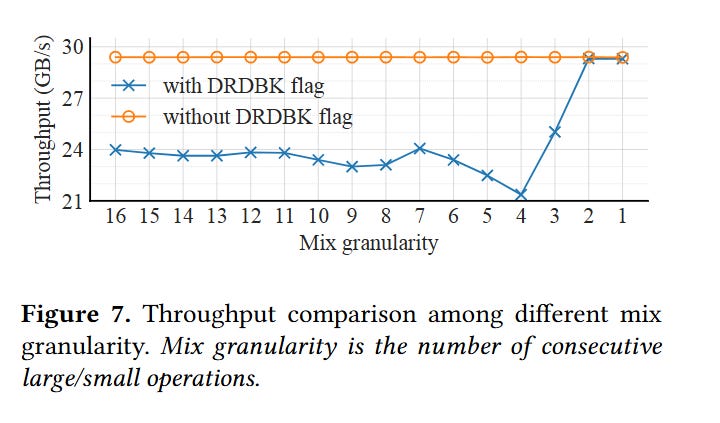
My takeaway is that DSA users should ensure that work and batch descriptors use the same traffic class, to avoid having to invoke this slow read-back path.
Out-of-order Completion
Because the DSA contains multiple engines, tasks can complete in a different order than the order in which they are submitted. This is fine in itself, but the authors note that software must take care to efficiently support allocating work and batch descriptors in light of this. Time spent bookkeeping to handle out-of-order completion is overhead that adds up for small tasks.
The solution proposed by this paper is for software to maintain two batch descriptor lists (free, and busy). When software needs to recycle descriptors from the busy list to the free list, it checks most (but not all) batch descriptors in the busy list to see if the hardware has completed the batch. This is in contrast to an approach which simply checks to see if the oldest-submitted batch has completed. The paper finds that it is optimal for the recycling process to ignore the 25 most recently submitted batch descriptors but check the completion status of all other outstanding batches.
Results
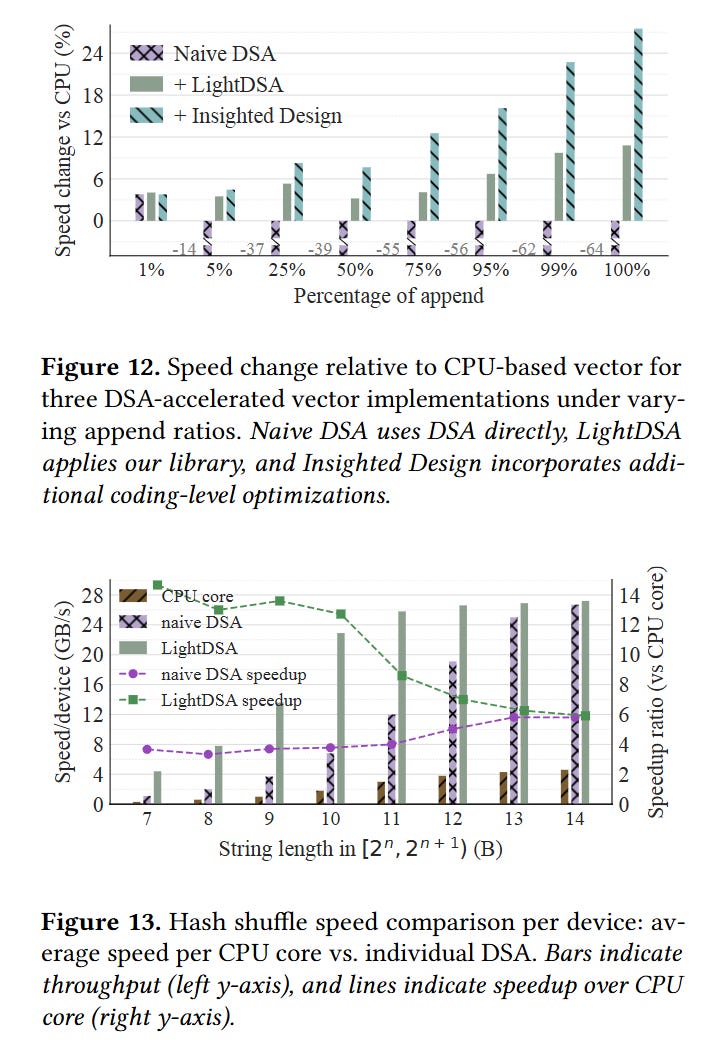
Figs. 12 and 13 compare the performance you can expect to see from using DSA naively versus using the techniques described in this paper (LightDSA). My takeaway is that the DSA is powerful, but only if you use it carefully.
Dangling Pointers
I suspect the elevator pitch for DSA is something like: “just re-compile your existing C/C++ code and all of the memcpy/memcmp time will be optimized out”. It seems like DSA falls short of that. I wonder if the elevator pitch would be better realized if application code was written in other languages (like an explicitly pipeline parallel language).