
To PRI or Not To PRI, That's the question
The downsides of fault-and-stall for PCIe devices

To PRI or Not To PRI, That's the question Yun Wang, Liang Chen, Jie Ji, Xianting Tian, and Ben Luo, Zhixiang Wei, Zhibai Huang, and Kailiang Xu, Kaihuan Peng, Kaijie Guo, Ning Luo, Guangjian Wang, Shengdong Dai, Yibin Shen, Jiesheng Wu, and Zhengwei Qi OSDI'25
Fast IO and Oversubscription
The problem this paper addresses comes from the tension between two requirements in cloud environments:
Fast, Virtualized, IO
DRAM oversubscription
PCIe has bells and whistles to enable fast, virtualized, IO. With Single Root I/O Virtualization (SR-IOV) a device (e.g., a NIC) can advertise many virtual functions (VFs). Each virtual function can be mapped directly into a VM. Each VF appears to a VM as a dedicated NIC which the VM can directly access. For example, a VM can send network packets without a costly hypervisor switch on each packet.
Oversubscription allows more VMs to be packed onto a single server, taking advantage of the fact that it is rare that all VMs actually need all of the memory they have been allocated. The hypervisor can sneakily move rarely used pages out to disk, even though the guest OS still thinks those pages are resident.
The trouble with putting these two (SR-IOV and DRAM oversubscription) together is that devices typically require that any page they access in host memory is pinned. In other words, the device cannot handle a page fault when doing a DMA read or write. This stops the hypervisor for paging out any page which may be accessed by an I/O device.
This paper describes the Page Request Interface (PRI) of PCIe, which enables devices to handle page faults during DMA. The trouble with this interface is that the end-to-end latency of handling a page fault is high:
Mellanox [20] and VPRI focus on optimizing the latency of the IOPF process, claiming that the entire IOPF handling cycle introduces a latency of a few hundred milliseconds.
A NIC cannot hide this latency, and thus a page fault causes packets to be dropped. Additionally, PRI is relatively new and does not have OS support in many VMs that are running in the cloud today.
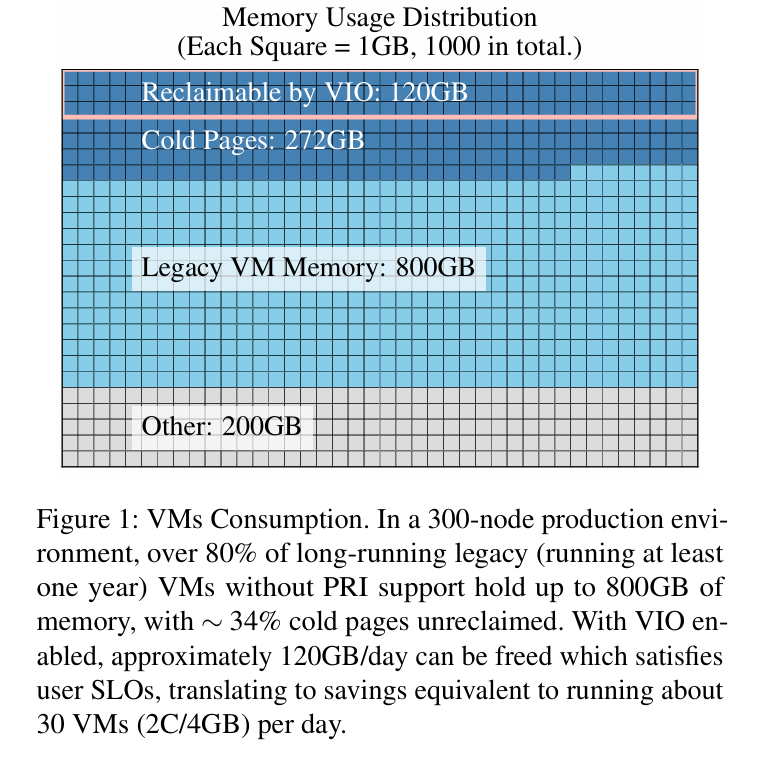
Fig. 1 shows data from a production environment which indicates that 30 additional VMs could be packed into the environment if SR-IOV could be made to not prevent DRAM oversubscription:
VM Categorization
Fig. 4 argues for a two-pronged approach (“there are two types of VMs in this world”):
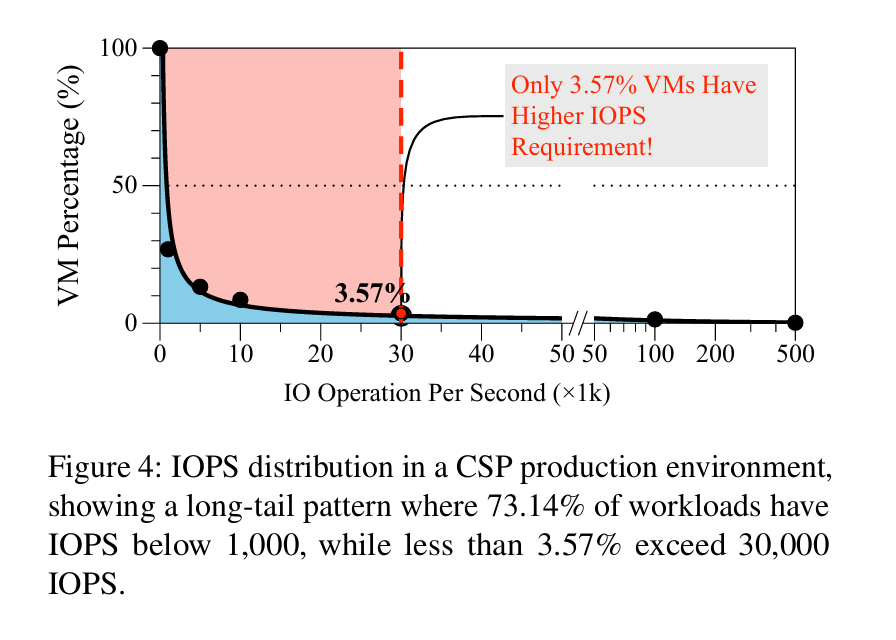
The key observation is that most VMs don’t do high frequency IO. The paper proposes to dynamically classify VMs into two IO frequency buckets:
For VMs with low frequency IO, the hypervisor is in the loop for each IO operation and moves pages between disk/DRAM to allow oversubscription. The paper calls this mode IOPA-Snoop.
For VMs with high frequency IO, the hypervisor ensures that all pages stay resident, and the hypervisor gets out of the way as much as possible. The paper calls this mode Passthrough.
At any point in time, most VMs are in IOPA-Snoop mode, and the hypervisor benefits from DRAM oversubscription for these VMs.
The engineering marvel here is that this system can be done without any changes to the guest OS. The fine print on that point is this system requires the guest OS to use VirtIO drivers.
Implementation
The system described in this paper leverages nested paging. Intel’s implementation is called Extended Paged Table (EPT). Each ring buffer used to communicate with the device (i.e., Native Ring) has a Shadow Ring buffer associated with it. EPT is used to atomically switch the guest VM between the two rings. Similarly, the I/O page table (IOPT) in the IOMMU is used to atomically switch the device between the two rings.
When operating in IOPA-Snoop mode, the guest OS writes packet descriptors into the shadow ring. A module in the hypervisor detects a change to the shadow ring, moves pages to/from disk as necessary, and then updates the native ring, thus triggering the device to perform the IO. When operating in elastic passthrough mode, the guest OS writes packet descriptors directly into the native ring, and the hardware processes them immediately.
Before transitioning from snoop to passthrough mode, the hypervisor disables DRAM oversubscription (and pages in all pages the device could possibly access). Section 3.3 has more details on how the transition is implemented.
Results
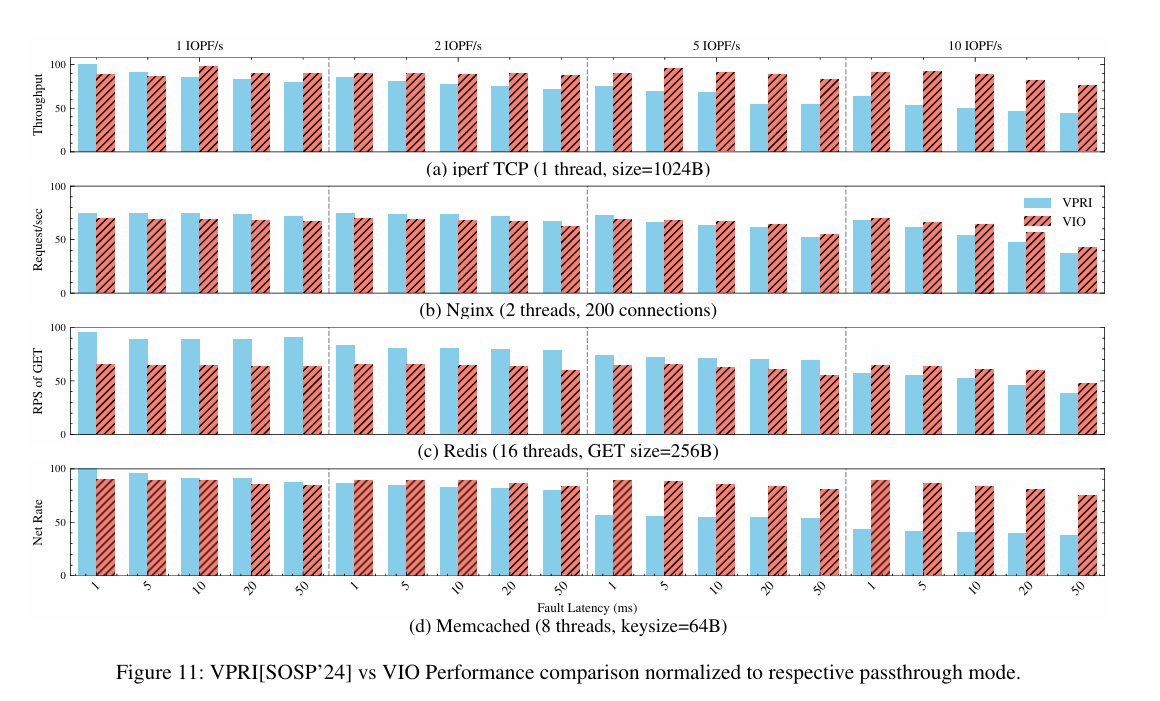
Fig. 11 shows throughput for IOPA-Snoop, Passthrough, and hardware-based page fault handling (i.e., VPRI). Results are normalized to passthrough throughput (i.e., 100 is the speed at which passthrough mode operates). The right-hand side shows the significant cost of hardware page fault handling.
Dangling Pointers
I wonder how much there is to be gained by a NIC-specific vertical solution. Disentangling the Dual Role of NIC Receive Rings indicates that there could be significant performance gained by cooperation between the NIC, hypervisor, and guest OS. For example, there could be a portion of host memory dedicated to hold packets received by the NIC, and this host memory could be dynamically shared between all guest VMs.