
Parendi: Thousand-Way Parallel RTL Simulation
RTL simulation on Graphcore chips

Parendi: Thousand-Way Parallel RTL Simulation Mahyar Emami, Thomas Bourgeat, and James R. Larus ASPLOS'25
This paper describes an RTL simulator running on (one or more) Graphcore IPUs. One nice side benefit of this paper is the quantitative comparisons of IPU synchronization performance vs traditional CPUs.
Here is another paper summary which describes some challenges with RTL simulation.
Graphcore IPU
The Graphcore IPU used in this paper is a chip with 1472 cores, operating with a MIMD architecture. A 1U server can contain 4 IPUs. It is interesting to see a chip that was designed for DNN workloads adapted to the domain of RTL simulation.
Partitioning and Scheduling
Similar to other papers on RTL simulation, a fundamental step of the Parendi simulator is partitioning the circuit to be simulated. Parendi partitions the circuit into fibers. A fiber comprises a single (word-wide) register, and all of the combinational logic which feeds it. Note that some combinational logic may be present in multiple fibers. Fig. 3 contains an example, node a3 is present in multiple fibers. As far as I can tell, Parendi does not try to deduplicate this work (extra computation to save synchronization).
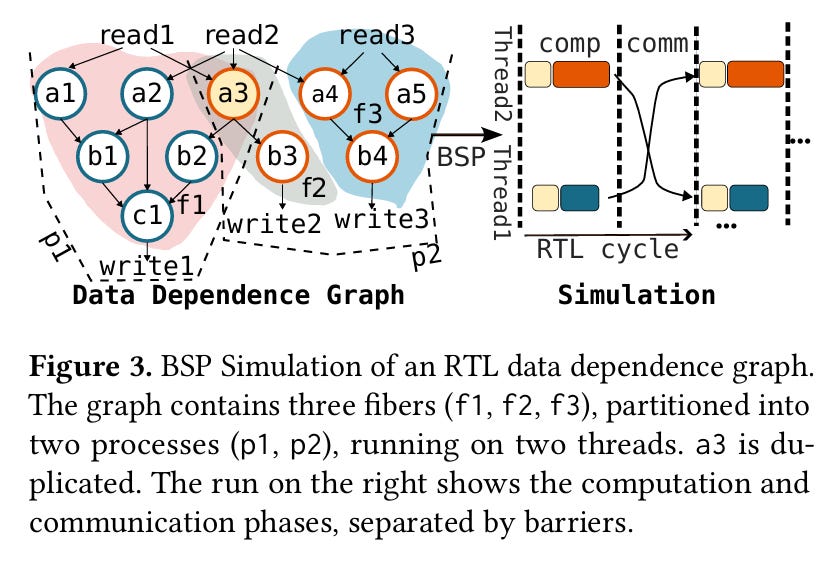
The driving factor in the design of this fiber-specific partitioning system is scalability. Each register has storage to hold the value of the register at the beginning and end of the current clock cycle (i.e., the current and next values).
I think of the logic to simulate a single clock cycle with the following pseudo-code (f.root is the register rooted at fiber f):
parallel for each fiber : f
f.root.next = evaluate f
barrier
parallel for each fiber : f
f.root.current = f.root.next
barrierScalability comes from the fact that there are only two barriers per simulated clock cycle. This is an instance of the bulk synchronous parallel (BSP) model.
Partitioning
In many cases, there are more fibers than CPU/IPU cores. Parendi addresses this by distributing the simulation across chips and scheduling multiple fibers to run on the same core.
If the simulation is distributed across multiple chips, then a min-cut algorithm is used to partition the fibers across chips while minimizing communication.
The Parendi compiler statically groups multiple fibers together into a single process. A core simulates all fibers within a process. The merging process primarily seeks to minimize inter-core communication. First, a special case merging algorithm merges multiple fibers which reference the same large array. This is to avoid communicating the contents of such an array across cores. I imagine this is primarily for simulation of on-chip memories. Secondly, a general-purpose merging algorithm merges fibers which each have low compute cost, and high data sharing with each other.
Results
Fig. 7 compares Parendi vs Verilator simulation. x64_ix3 is a 2-socket server with 28 Intel cores per socket. x64_ae4 is a 2-socket server with 64 AMD cores per socket:

Section 6.4 claims a roughly 2x improvement in cost per simulation using cloud pricing.
Dangling Pointers
As far as I can tell, this system doesn’t have optimizations for the case where some or all of a fiber’s inputs do not change between clock cycles. It seems tricky to optimize for this case while maintaining a static assignment of fibers to cores.
Fig. 4 has a fascinating comparison of synchronization costs between an IPU and a traditional x64 CPU. This microbenchmark loads up the system with simple fibers (roughly 6 instructions per fiber). Note that the curves represent different fiber counts (e.g., the red dotted line represents 7 fibers on the IPU graph, vs 736 fibers on the x64 graph). The paper claims that a barrier between 56 x64 threads implemented with atomic memory accesses consumes thousands of cycles, whereas the IPU has dedicated hardware barrier support.
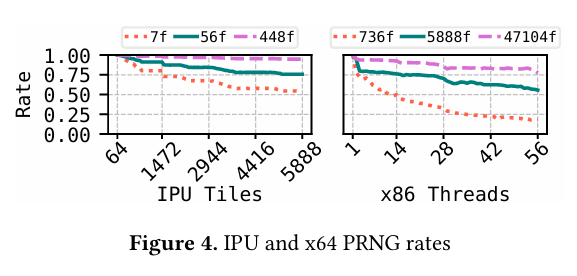
This seems to be one of many examples of how generic multi-core CPUs do not perform well with fine-grained multi-threading. We’ve seen it with pipeline parallelism, and now with the BSP model. Interestingly, both cases seem to work better with specialized multi-core chips (pipeline parallelism works with CPU-based SmartNICs, BSP works with IPUs). I’m not convinced this is a fundamental hardware problem that cannot be addressed with better software.