
No Cap, This Memory Slaps: Breaking Through the Memory Wall of Transactional Database Systems with Processing-in-Memory
PIM for OLTP (with a hilarious title)

No Cap, This Memory Slaps: Breaking Through the Memory Wall of Transactional Database Systems with Processing-in-Memory Hyoungjoo Kim, Yiwei Zhao, Andrew Pavlo, Phillip B. Gibbons VLDB'25
This paper describes how processing-in-memory (PIM) hardware can be used to improve OLTP performance. Here is a prior paper summary from me on a similar topic, but that one is focused on OLAP rather than OLTP.
UPMEM
UPMEM is specific PIM product (also used in the prior paper) on this blog. A UPMEM DIMM is like a DRAM DIMM, but each DRAM bank is extended with a simple processor which can run user code. That processor has access to a small local memory and the DRAM associated with the bank. This paper calls each processor a PIM Module. There is no direct communication between PIM modules.
Fig. 2 illustrates the system architecture used by this paper. A traditional CPU is connected to a set of boring old DRAM DIMMs and is also connected to a set of UPMEM DIMMs.
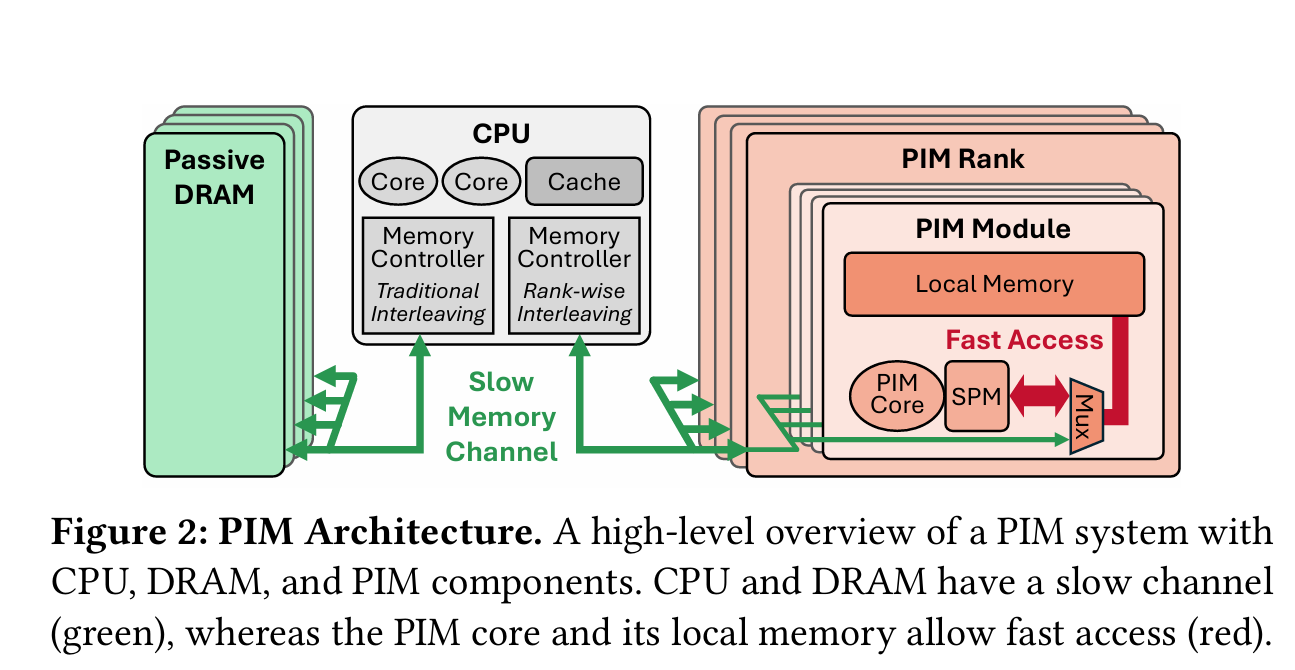
Four Challenges
The paper identifies the following difficulties associated with using UPMEM to accelerate an OLTP workload:
PIM modules can only access their local memory
PIM modules do not have typical niceties associated with x64 CPUs (high clock frequency, caches, SIMD)
There is a non-trivial cost for the CPU to send data to UPMEM DIMMs (similar to the CPU writing data to regular DRAM)
OLTP workloads have tight latency constraints
Near Memory Affinity
The authors arrived at a solution that both provides a good speedup and doesn’t require boiling the ocean. The database code and architecture remain largely unchanged. Much of the data remains in standard DRAM DIMMs, and the database operates on it as it always has.
In section 3.2 the authors identify a handful of data structures and operations with near-memory affinity which are offloaded. These data structures are stored in UPMEM DIMMs, and the algorithms which access them are offloaded to the PIM modules.
The key feature that these algorithms have in common is pointer chasing. The sweet spots the authors identify involve a small number of parameters sent from the CPU to a PIM module, then the PIM module performing multiple roundtrips to its local DRAM bank, followed by the CPU reading back a small amount of response data. The roundtrips to PIM-local DRAM have lower latency than accesses from a traditional CPU core.
Hash-Partitioned Index
One data structure which involves a lot of pointer chasing is B+ tree traversal. Thus, the system described in this paper moves B+ tree indexes into UPMEM DIMMs and uses PIM modules to search for values in an index. Note that the actual tuples that hold row data stay in plain-old DRAM.
The tricky part is handling range queries while distributing an index across many banks. The solution described in this paper is to partition the set of keys into 2R partitions (the lower R bits of a key define the index the partition which holds that key). Each partition is thus responsible for a contiguous array of keys. For a range query, the lower R bits of the lower and upper bounds of the range can be used to determine which partitions must be searched. Each PIM module is responsible for multiple partitions, and a hash function is used to convert a partition index into a PIM module index.
MVCC Chain Traversal
MVCC is a concurrency control method which requires the database to keep around old versions of a given row (to allow older in-flight queries to access them). The set of versions associated with a row are typically stored in a linked list (yet another pointer traversal). Again, the actual tuple contents are stored in regular DRAM, but the list links are stored in UPMEM DIMMs, with the PIM modules traversing the links. Section 4.3 has more information about how old versions are eventually reclaimed with garbage collection.
Results
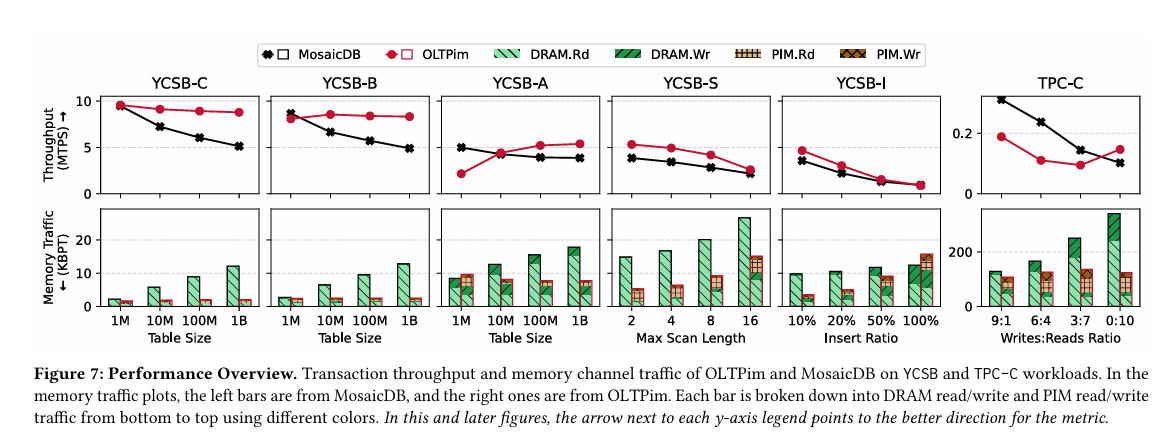
Fig. 7 has the headline results. MosaicDB is the baseline, OLTPim is the work described by this paper. It is interesting that OLTPim only beats MosaicDB on TPC-C for read-only workloads.
Dangling Pointers
Processing-in-memory can help with memory bandwidth and memory latency. It seems like this work is primarily focused on memory latency. I suppose this indicates that OLTP workloads are fundamentally latency-bound, because there is not enough potential concurrency between transactions to hide that latency. Is there no way to structure a database such that OLTP workloads are not bound by memory latency?
It would be interesting to see if these tricks could work in a distributed system, where the PIM modules are replaced by separate nodes in the system.