
RayN: Ray Tracing Acceleration with Near-memory Computing
Fast Pointer Chasing in HBM

RayN: Ray Tracing Acceleration with Near-memory Computing Mohammadreza Saed, Prashant J. Nair, and Tor M. Aamodt MICRO'25
A previous paper on OLTP acceleration with processing-in-memory hardware came to the conclusion that the ripest fruit to pick is pointer chasing. This paper comes to a similar conclusion for a different application: ray tracing.
BVH Traversal
Ray tracing applications spend most of their time traversing a bounding volume hierarchy (BVH) which contains the scene to be rendered. The BVH data structure analyzed in this paper is a tree, where each node in the tree contains an axis-aligned bounding box which bounds the subtree rooted at that node. To determine which part of the scene a ray intersects, a ray tracer traverses the BVH starting at the root and recursing if the ray intersects the bounding box of the current node. A typical BVH is large and does not fit into on-chip memory.
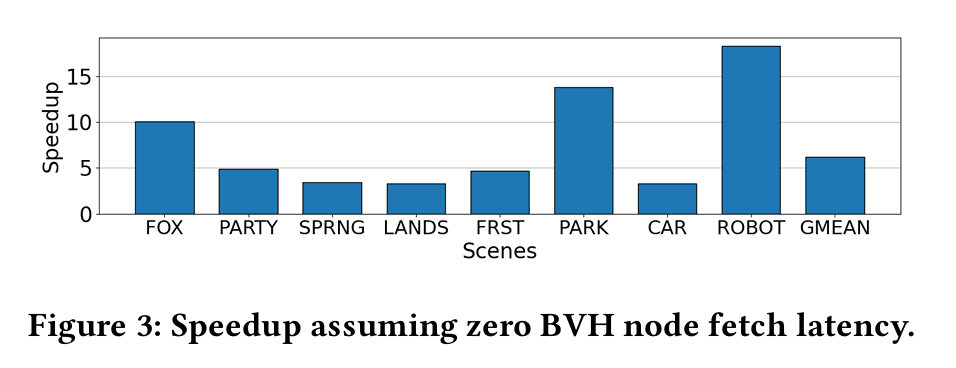
The problem with this process is that it is not coherent. If a bundle of 8 rays are processed together, one would hope that the traversals performed by each ray are similar, but alas, they frequently are not. This means that the cost of reading BVH nodes from off-chip memory cannot be amortized across many rays. Fig. 3 shows the potential speedup if BVH reads were free:
BVH Traversal in HBM Logic Dies
Fig. 5 shows a GPU with four HBM stacks:
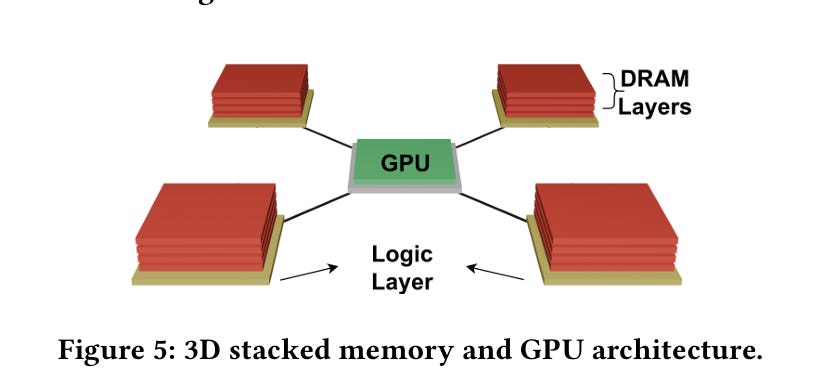
The yellow rectangles at the bottom of each stack are the key here: each one is an HBM logic die, which can implement a modest amount of functionality. The potential speedup comes from the fact that the BVH traversal logic in the HBM logic die has a much lower latency when accessing its local BVH data and thus can traverse the BVH faster than the GPU can.
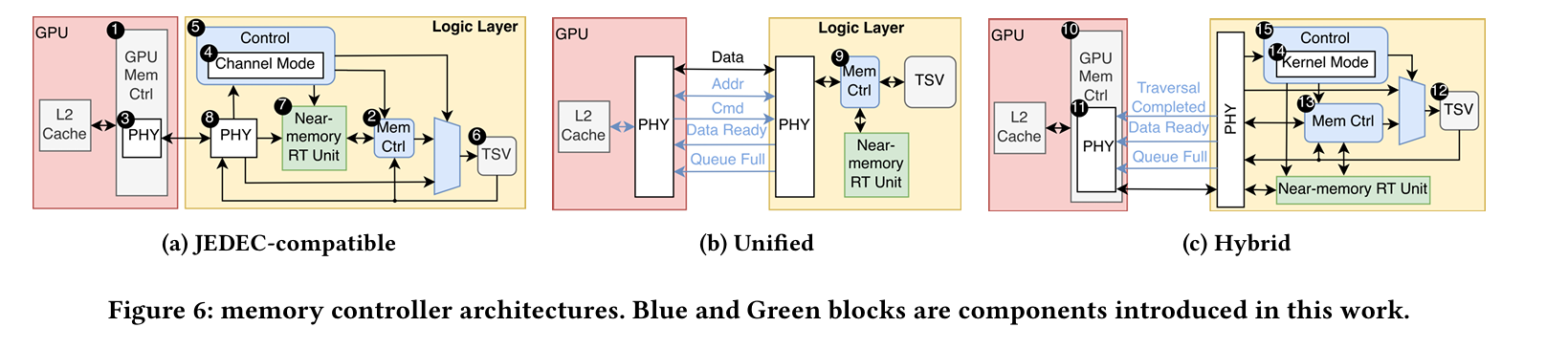
Typical GPUs contain sophisticated memory controllers. These are implemented in the GPU directly because the GPU die is the best location for complex (i.e., heat-generating) logic. The authors propose three designs for integrating simple BVH traversal logic into HBM logic dies:
JEDEC-compatible: the GPU retains its sophisticated memory controller, and the HBM logic die integrates a simple memory controller and BVH traversal logic. At any one time, a particular HBM stack can be used for general compute or ray tracing. The driver on the host OS controls this configuration at a coarse granularity.
Unified: Add a memory controller and BVH traversal logic to the HBM logic die. Remove the memory controller from the GPU. This avoids having to partition HBM stacks, but potentially limits the sophistication of the memory controller, and requires significant changes to the GPU.
Hybrid: there are memory controllers in both the GPU and HBM logic dies, but both can be active at the same time. When both are active, the GPU memory controller sends requests to the HBM logic die controller, which interleaves these requests with requests coming from the BVH traversal logic on the logic die. This scheme requires larger GPU changes than the JEDEC-compatible option but avoids coarse-grain partitioning.
Fig. 6 illustrates these three designs:
BVH Partitioning
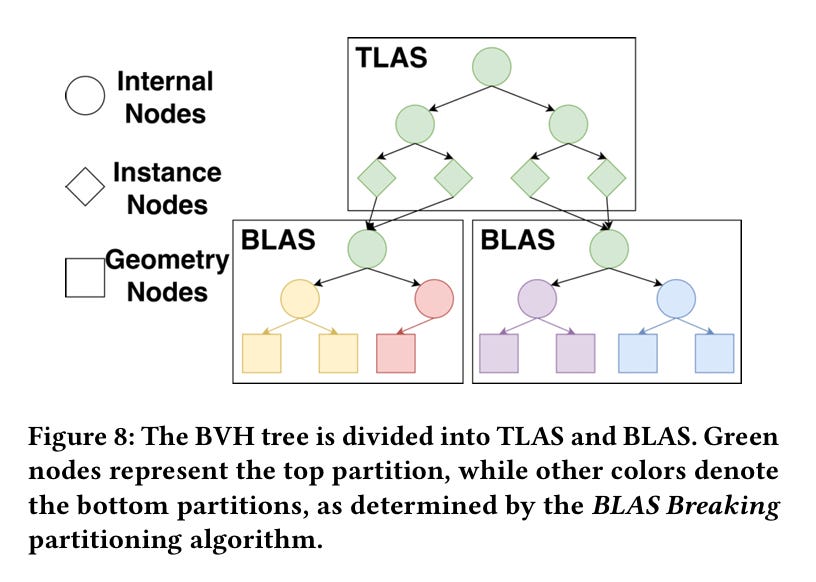
A recurring puzzle with processing-in-memory applications is how to partition across memory modules in a way that doesn’t cause load imbalance. The authors of this paper propose that the root of the BVH and nodes which are close to the root should be accessed by the GPU as they normally would be. The proposed design builds on a common two-level BVH implementation for GPUs.
In these implementations, the BVH is divided into the top-level acceleration structure (TLAS) and bottom-level acceleration structures (BLAS). The TLAS contains the root and some interior nodes, each BLAS contains other interior nodes, and leaf nodes. One key design choice here is that multiple instances of a BLAS can appear in a scene (e.g., a single BLAS describes a fish, and the scene can contain 15 fishes). In this case, the TLAS contains multiple pointers to a single BLAS.
The paper examines many alternative designs and concludes that BLAS Breaking (BB) is the optimal approach. In this design the GPU treats the TLAS and top-level nodes of each BLAS as normal and lets the BVH traversal logic in the logic dies only handle traversal of nodes near the leaves in each BLAS.
There are two reasons for this design. The first is that the memory coherence problem grows in significance the further away from the root a bundle of rays gets (i.e., near the root of the BVH, all rays in a bundle will typically follow similar paths). The second reason is that it would be complex to support ray tracing acceleration of the TLAS because multiple instances of each BLAS may exist. This would require the ray tracing units in the HBM logic dies to communicate with each other.
Subtrees within a BLAS are partitioned among the HBM stacks. Fig. 8 illustrates an example BVH. Green nodes are processed by the GPU as they normally would be. Once a subtree of another color is reached, the rest of the BVH traversal is handled by the logic die in the HBM stack indicated by the color of the subtree.
Fig. 8 illustrates a BVH which has been partitioned with BLAS Breaking:
Results
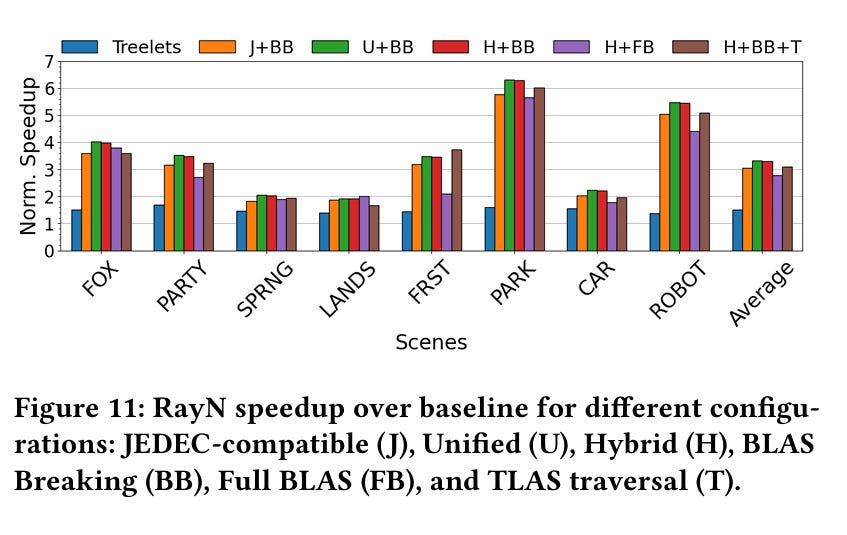
Fig. 11 has simulated speedups, comparing various designs to a baseline that does not have ray tracing offloads in HBM logic dies. U+BB (unified memory controller + BLAS breaking) is the approach advocated by this paper.
Dangling Pointers
If the ray tracing logic in the HBM die is bound by memory latency, I wonder if it needs to be so specialized. Maybe one could get away with more general-purpose logic there (e.g., UPMEM processors) and still get similar results for ray tracing applications.
Excellent treatment of BVH coherence challenges. The BLAS Breaking partition strategy makes sense given the diminishing coherence at deeper tree levels, but I'm curious how this handles dynamic scenes where BLAS topologies change per frame. The unified controller approach sidesteps the coarse-grain partitioning issue nicley, though moving controller logic off-die does introduce verification complexity. The 1.8x geomean speedup is solid for what amounts to specialized pointer-chasing hardware.