
Accelerating Transactional Execution via Processing-In-Memory
OLTP in UPMEM

Accelerating Transactional Execution via Processing-In-Memory André Lopes, Daniel Castro, and Paolo Romano EUROSYS'26
This paper describes a way to implement OLTP for a processing-in-memory architecture. As with other academic research, it uses UPMEM (here are two summaries of papers that rely on UPMEM). Something I found surprising in this work is conflicts can cause transactions to abort, even if all transactions only access data in the same UPMEM bank.
UPMEM Refresher
A UPMEM DIMM is like a DRAM DIMM, but each bank contains a multi-threaded in-order core which can access data from the bank it is co-located with. This paper calls these processors DPUs (some other papers call them IDPs). The only way for two DPUs to communicate with each other is for the host CPU to read data from one bank and write it into another.
PIM-TIDE
The system described in this paper is called PIM-TIDE. It assumes that transactions come pre-sliced into computational graphs comprising subtransactions. A single subtransaction only accesses data within one bank (and thus executes on a specific DPU). Users of PIM-TIDE do not need to know exactly which data words a subtransaction will access, but they do need to be able to restrict a subtransaction to only access data from a specific bank. This works well on TPC-C style transactions where most of the database can be partitioned on warehouse_id.
The host CPU groups transactions into batches and sends work to the DPUs one batch at a time. Within a batch, transactions are categorized into two groups:
Local transactions execute entirely within a DPU
Distributed transactions execute across multiple DPUs
All subtransactions associated with distributed transactions within a batch are assigned a unique sequence number, which determines the order in which the subtransactions will commit. Local transactions are not preassigned to a commit order. DPUs first process all distributed subtransactions in a batch and then execute all local subtransactions.
Concurrency Control
Algorithm 3 illustrates PIM-TIDE’s concurrency control scheme for dealing with intra-DPU conflicts between subtransactions. LOCK_TABLE is stored in fast on-chip memory and is indexed by a hash of the word address. If a transaction aborts, state can be rolled back and the transaction is retried. All transactions assigned to a DPU will commit eventually. Inter-DPU conflicts are handled by deterministic concurrency control (i.e., the pre-assigned sequence numbers).

Results
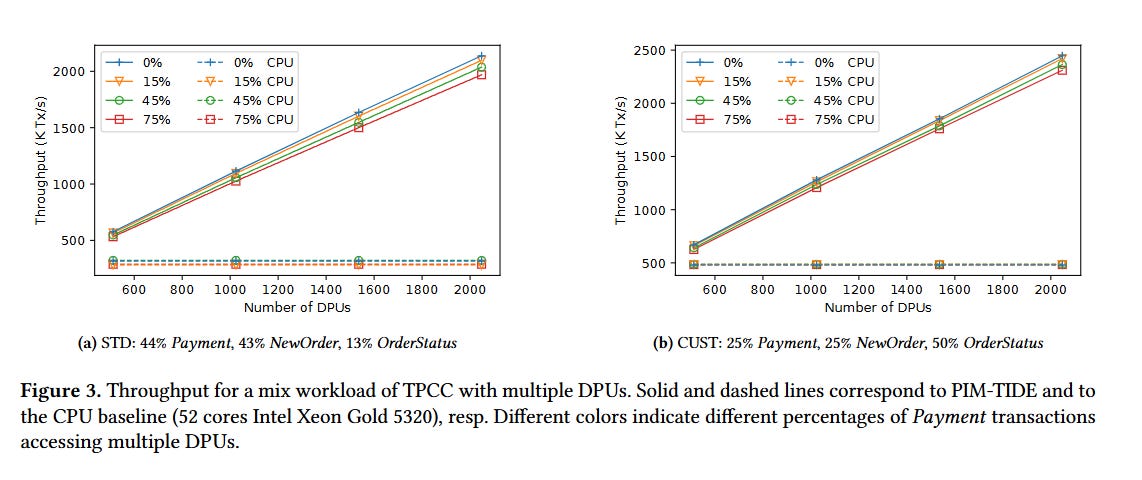
Fig. 3 compares performance of PIM-TIDE vs a CPU baseline for a mix of TPC-C transactions, wow that is a significant speedup. I believe all transactions/subtransactions are written by hand in C code that is compatible with UPMEM DPUs.
Dangling Pointers
TPC-C is easy to partition; I wonder how well PIM-TIDE does on workloads that are not as partitionable. Also, this scheme doesn’t seem to allow for interactive transactions, how important are those in the real world?