
CEIO: A Cache-Efficient Network I/O Architecture for NIC-CPU Data Paths
Walking on DDIO Eggshells

CEIO: A Cache-Efficient Network I/O Architecture for NIC-CPU Data Paths Bowen Liu, Xinyang Huang, Qijing Li, Zhuobin Huang, Yijun Sun, Wenxue Li, Junxue Zhang, Ping Yin, and Kai Chen SIGCOMM'25
Thanks to antonio gramsci for the pointer to this paper.
DDIO Refresher
CEIO tries to solve the same problems as Disentangling the Dual Role of NIC Receive Rings (which proposes a solution named rxBisect). Here is a rehash from my summary of that paper:
DDIO is a neat feature of Intel CPUs which causes the uncore to direct writes from I/O devices such that data lands in the LLC rather than main memory. In effect, DDIO speculates that a CPU core will read the data before it is evicted from the LLC. This feature is transparent to the I/O device.
The particular problem the CEIO paper addresses is called Leaky DMA in the rxBisect paper, so let’s stick with that. Recall the Leaky DMA problem occurs when the sum total of all per-core receive rings is too large, and thus the working set of the system no longer fits in the LLC. In this situation, when the NIC writes data for a packet into the LLC, it ends up inadvertently evicting data associated with an older packet. This defeats the whole purpose of DDIO.
Credit-Based Flow Control
The core idea of CEIO is for the NIC to track per-flow (flow and connection are used interchangeably in this paper) credits. When a new packet arrives, the NIC decrements credits from the associated flow and then sends the packet to host memory. If no credits are available, then the NIC stuffs the packet in DRAM that is local to the NIC (this paper assumes a NIC like nVidia BlueField-3 with 16GB of local DRAM). The sum of the credits across all flows is sized such that LLC capacity will not be exceeded when all credits are in use. The case where credits are available is called the fast path, the other case is called the slow path. Section 4.2 of the paper goes into the details of how the system correctly switches back and forth between the slow and fast paths.
Credits are tracked in increments of 64 bytes, and the number of credits a packet consumes is proportional to the size of the packet. The CEIO driver running on the host returns per-flow credits to the NIC via register writes after the CPU has finished reading a packet.
An ARM core on the NIC handles allocation of credits to flows. Credit allocation is unashamedly fair and balanced. The desired total number of credits per flow is simply the total number of credits the LLC can support, divided by the number of flows. When a new connection is established, the flow allocator reallocates available credits from existing flows. If a given flow has too many credits allocated to it, but those credits are all in use, then the allocator records that the flow is “in credit debt” and rectifies the situation when the CEIO driver on the host returns credits to the indebted flow.
Results
The authors implemented CEIO on a BlueField-3 NIC. Fig. 9(a) compares throughput and LLC miss rates of CEIO with other implementations. This particular comparison represents static network conditions (no new flows coming and going, skew properties not changing).
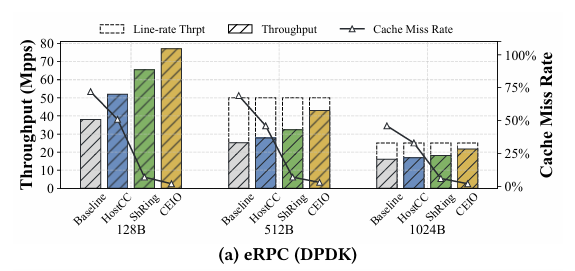
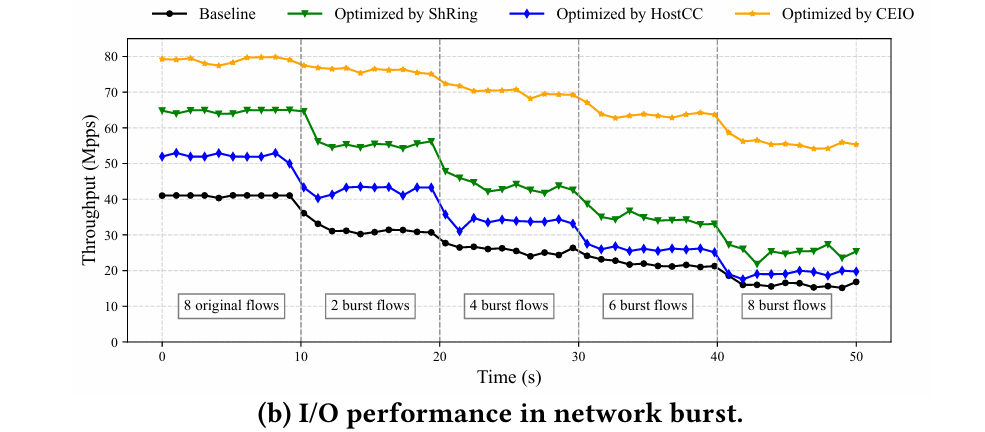
Fig. 10(b) shows throughput in bursty conditions:
CEIO vs rxBisect
One advantage CEIO has is that it tracks credits at 64-byte granularity. The design of rxBisect requires tracking credits at MTU granularity, which will be less efficient for small packets.
rxBisect doesn’t require DRAM local to the NIC, which makes it applicable to cheaper hardware.
What happens after the host CPU has processed a packet? With rxBisect, it is unlikely that the packet will be evicted from the LLC, whereas with CEIO the packet likely will be evicted (thus wasting DRAM bandwidth writing data that is never needed again). This is because with rxBisect, the sum of all credits (the sum of the sizes of all Ax rings) is sized to fit in the LLC, whereas with CEIO only the set of all pending packets (those not yet processed by the CPU) will be in the LLC. Necro-reaper proposes another solution to this dead writeback problem.
Dangling Pointers
It seems like there is mounting evidence that DDIO is missing a coordination interface to allow it to reliably work. Hardware designs and drivers need to walk on eggshells to take advantage of DDIO.
One incremental change would be to allow hardware to hint that a particular DMA write should not land in the LLC. That would enable CEIO to work with NICs that do not have local DRAM, the slow path could write data into host DRAM instead.
i agree with your conclusions :) i wonder if it would be possible to add the no-cache-request to the tlp hints, like amd does