
SG-IOV: Socket-Granular I/O Virtualization for SmartNIC-Based Container Networks
Socket-level NIC Virtualization

SG-IOV: Socket-Granular I/O Virtualization for SmartNIC-Based Container Networks Chenxingyu Zhao, Hongtao Zhang, Jaehong Min, Shengkai Lin, Wei Zhang, Kaiyuan Zhang, Ming Liu, and Arvind Krishnamurthy ASPLOS'26
SR-IOV Scalability
SR-IOV is a PCIe feature that enables a single device to expose multiple virtual functions, each of which appears as a separate device. This can be used to securely share one hardware device among multiple virtual machines.
For containerized workloads, one would think that SR-IOV could be used to expose a virtual NIC to each container. This would save CPU cycles as network virtualization would be handled by the NIC rather than software.
The trouble is that SR-IOV doesn’t scale to high container counts (they top out on the order of 100 of virtual functions per physical NIC). This paper introduces Socket-Granular I/O Virtualization (SG-IOV) which enables NIC virtualization at the socket level. The authors have an implementation working on NVIDIA BlueField-3.
Streams vs Packets
The key assumption that SG-IOV makes is that container networking uses stream sockets (e.g., TCP) rather than datagram sockets (e.g., UDP). In other words, software running inside a container wants to reliably send a stream of bytes rather than a stream of packets.
Streams are transmitted through Warp Pipes, which are simply ring buffers (comprising a base address, head and tail pointers). Warp Pipes can be stored in host memory or NIC local memory. A socket is associated with one or more dedicated Warp Pipes. A server can have thousands of Warp Pipes, because the low-level NIC hardware (which may have scalability limits) doesn’t directly interact with Warp Pipes.
Signaling
Updates to head and tail pointers are not performed directly via memory writes, instead they are communicated through a Cross-FIFO. A single message in a cross-FIFO contains three fields:
Ring buffer ID (which Warp Pipe to update)
Which pointer to update (head or tail)
The new value of the head or tail pointer
There are multiple implementations of the Cross-FIFO interface. For example, the authors use a PCIe-based implementation for host→NIC communication, and a RDMA based implementation for NIC→NIC communication.
Each cross-FIFO uses limited NIC resources; therefore many sockets share a single cross-FIFO, which is OK because the messages they contain are coarse-grain (e.g., increment tail pointer by 16KiB).
Flow
Say an application in container A on host 1 wants to send 8KiB of data to an application in container B on host 2. The flow looks like this:
Host CPU (host 1):
The application calls the standard socket
send()APIThe payload is copied into the Warp Pipe associated with the socket
A message is enqueued into a PCIe cross-FIFO, indicating that the head pointer should be incremented by 8KiB
ARM CPU running on the NIC (host 1):
Dequeue the message from the cross-FIFO, update the head pointer
Enqueue task descriptors to the low-level NIC hardware to read the payload data (i.e., local DMA) from the Warp Pipe and store it in the correct Warp Pipe on host 2 (i.e., RDMA); note that these task descriptors can configure the NIC to perform appropriate network virtualization
After the data has been transmitted, enqueue a message to the NIC on host 2 (via a RDMA-based cross-FIFO) to update the head pointer for the Warp Pipe on host 2
ARM CPU running on the NIC (host 2):
Dequeue the message from the cross-FIFO
Update the local head pointer
Enqueue a message to the host CPU (host 2) via a PCIe-based cross-FIFO, indicating that the head pointer should be incremented
Host CPU (host 2):
Dequeue the message from the PCIe-based cross-FIFO
Send data to the application when it calls
recv()
And a similar sequence would update tail pointers.
The key design principles of SG-IOV are:
All state is tracked by software running on the host CPU and ARM CPUs running on the NIC
All low-level NIC hardware is used in a stateless manner, and is multiplexed across many sockets
A benefit of this design is that it is flexible enough to handle the loopback case efficiently.
Results
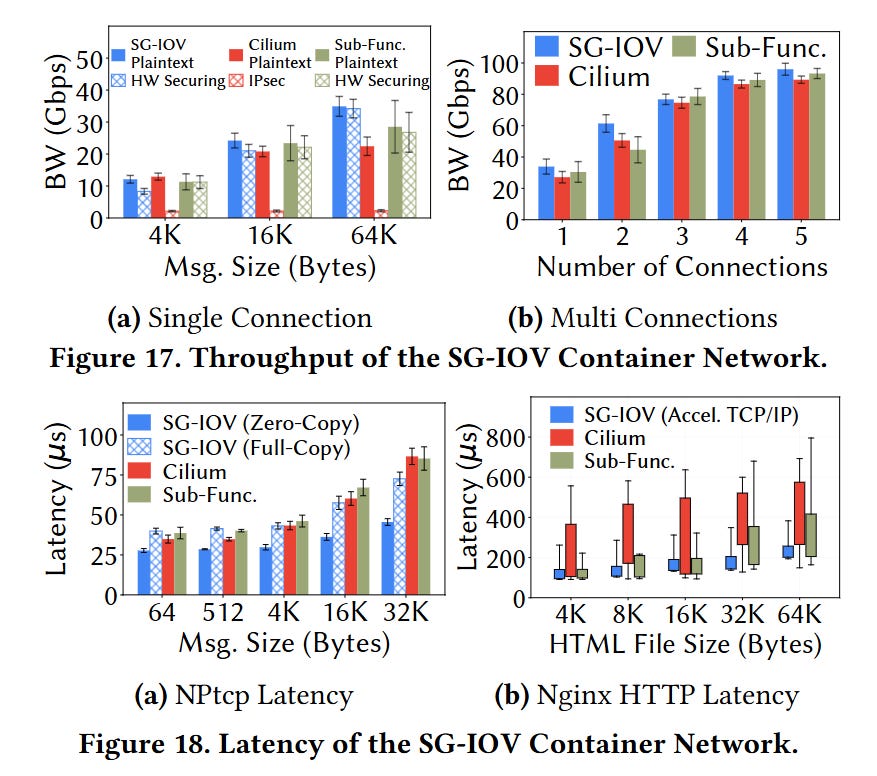
Section 8 of the paper shows that SG-IOV enables the use of hardware-accelerated network virtualization (saving host CPU cycles) while offering latency and bandwidth that is competitive with other container-based network virtualization systems.
Figs. 17 and 18 show latency and bandwidth numbers for a few benchmarks:
Dangling Pointers
It seems like one downside of this system is excessive memory usage. If each socket has dedicated large ring buffers, then DDIO may not be effective (see here, here, and here for other papers that discuss this problem).